前端是怎么解析Excel、PDF、Word、PPT等文件的?
当前位置:点晴教程→知识管理交流
→『 技术文档交流 』
一、写在前面作为一名开发者,大家在开发过程中是不是经常遇到各种各样的文件,比如xlsx、word、ppt等办公类型的文件格式,还有pdf这种便携式的打印格式文件等。 但是通常情况下我们都是使用一个相关的第三方库,比如用 sheet.js 来解析xlsx,mammoth.js 来解析wrod,pptxjs 来解析ppt,如果这些库你不知道的话,你可以好好研究一下他们的文档,照着文档满足你的业务需求是肯定没问题的。 但是本文并不尝试跟大家过一遍这些库是如何使用的,因为笔者认为做一个API调用工程师意义并不大,本文的目的是跟大家分享这些文件的本质,从而能够在平常的开发中即便遇到棘手的问题,大家也能够从容的解决,而不会被第三方库所绑架。 如果你对以下问题有兴趣,那么仔细阅读本篇文章,你一定会有收获!
准备好我们开始发车! let`s get start it! 二、办公文件的本质历史中国的 蔡伦 在公元105年发明了造纸术,它让人们进入了一个崭新的时代。从此纸张如一头猛兽闯入千家万户,人们可以在纸张上记录、编写、传播信息。 技术的突破往往会催生出新的需求,这种在纸张上记录、编写、和传播信息的需要渐渐成为人们生活不可或缺的一部分,历史、文学、科学、艺术、日常事物都需要依赖于这种技术,因为承载了信息,纸张慢慢被人们称为文件,无论从哪个角度来看,文件的出现都是人类文明史上浓墨重彩的一笔。 纸张统治了世界将近2000年,或许未来在相当长的时间内它还将一直存在,但是20世纪末,互联网的出现让纸质的文件地位出现了动摇,甚至大有退出历史舞台的趋势。人们发现将一切的纸张文件电子化会有令人意想不到的收益。电子文件传播更迅速、编写更方便、记录更便捷。尤其是个人PC和移动终端的出现让人们随时随地可以记录、编写、传播信息。 最早推动这一过程的是王安电脑公司在1971年推出WPS文字处理机-Wang 1200打印机,之后王安WPS成为美国每间办公室的必备。
后续又有诸多的公司参与这场世纪之战,这个过程诞生了许许多多的办公设备,他们有软件也有硬件,它们的出现加速了这场文件数字化的革命。微软办公软件是这场战役的胜利者,在全球市场上一直占据主导地位。Microsoft Office套件是业界最受欢迎和广泛使用的办公软件套装之一。该套件包括诸如Word、Excel、PowerPoint等应用程序,它们在文档处理、电子表格和演示方面提供了强大的功能。 遗憾的是历史只记录胜利者,如果你希望了解更多办公软件历史,可以读读这篇文章 标准大家是否思考过一个问题,为什么你创建了一个Word文档之后,既可以使用微软在Windows电脑中预装的Office软件打开,也可以使用金山软件的WPS打开。实际上市面上的办公软件其实非常的多,比如:Google Workspace (以前称为 G Suite):、 LibreOffice:、 Apache OpenOffice:、 Apple iWork:、 Zoho Office Suite 。 不知道你是否好奇,为什么对于同一份word文档,这些不同厂商的软件无一例外的都可以打开进行阅读和编辑。 这是为什么呢? 原来他们都遵循同一套标准,这套标准叫做
这套标准定义了各种各样的组件例如:段落、表格、图片、布局等如何使用xml语言来进行描述,因此各个办公软件厂商只要遵循这套规范就可以解析对应的Word文件,当用户保存文件时它们也都会遵循这套规范去生成一份Word文件以便用户使用其他软件可以正常使用,就这样大家遵纪守法,其乐融融。
压缩包如果是经常使用办公软件的同学有这样的体会,当我使用LibreOffice创建一个Word文档时会生成一个.odt的文件,如下图所示:
当我使用Microsoft Office创建一个Word文档时,会生成一个.doc或者.docx的文件。
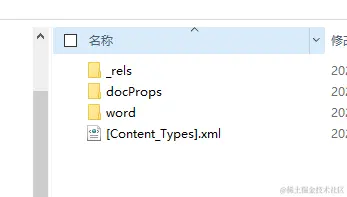
或许其他的软件还有其他的名字,如果你有兴趣可以试一下,不管这个后缀是什么名字,甚至你自己随便改个后缀,只要它是遵循上面我们提到的标准生成的,它都可以被所有主流的办公软件识别和正常使用。 想必计算机专业的同学或许都知道后缀名其实就是一个标识而已,帮助不同的软件去匹配对应的logo标识而已。而这个文件的本质其实就是个压缩包。而当你把这个压缩包解析之后,你就会得到一个文件夹里面全部都是xml和相关的配置文件。 你可以选择把你的word文档后缀改成
每个文件夹下面几乎都是清一色的.xml文件和少数的配置文件。不止word文档是如此、excel文件、ppt文件都可以按照上面的操作如法炮制,都可以得到一个文件夹,但遗憾的是pdf不是,我们后面再揭晓pdf的本质。
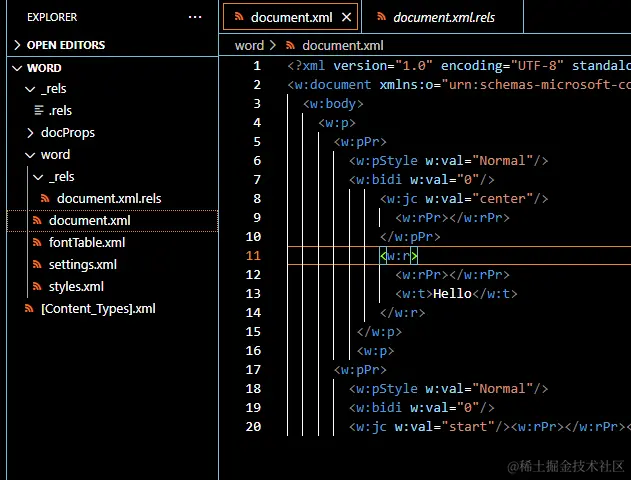
XML如果是计算机专业的同学,对xml或许应该比较熟悉,但是我依然嘴碎一下,照顾下非计同学。 xml本质上就是一个文本文件,只不过文件后缀是 <w:jc w:val="center"/> <w:rPr></w:rPr></w:pPr><w:r> <w:rPr></w:rPr> <w:t>Hello</w:t></w:r>解压后的word就有类似下面的xml文件
实际上前端同学所熟悉的html就是一种特殊的xml,同属于标记语言,所以前端同学看到xml会有一种奇怪的熟悉感,更重要的是,在浏览器中是可以直接解析xml的,所以在浏览器端我们就不用通过字符串的方式自己实现解析的算法。解析的例子如下: <html lang="en"><head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>XML 解析示例</title></head><body><h1>XML 解析示例</h1><script>
// 假设有以下 XML 数据
var xmlData = `
<employees>
<employee>
<id>1</id>
<name>John Doe</name>
<position>Developer</position>
</employee>
<employee>
<id>2</id>
<name>Jane Smith</name>
<position>Designer</position>
</employee>
</employees>
`;
// 创建 DOMParser 对象
var parser = new DOMParser();
// 使用 DOMParser 解析 XML 字符串
var xmlDoc = parser.parseFromString(xmlData, "text/xml");
// 获取 XML 中的元素
var employees = xmlDoc.getElementsByTagName("employee");
// 遍历元素并输出内容
for (var i = 0; i < employees.length; i++) {
var id = employees[i].getElementsByTagName("id")[0].textContent;
var name = employees[i].getElementsByTagName("name")[0].textContent;
var position = employees[i].getElementsByTagName("position")[0].textContent;
console.log("Employee ID: " + id);
console.log("Name: " + name);
console.log("Position: " + position);
console.log("--------------------");
}</script></body></html> 可以看到只要给前端一份xml文件我们就可以通过DOM相关的API拿到任何我们想要的东西。 解析那么为什么前端可以解析excel、word、ppt等文件呢? 原因其实很简单,因为解析需要满足的条件前端都具备。首先浏览器可以读取磁盘的文件,如果想要了解浏览器如何读取磁盘的细节,我之前写过这篇文章欢迎你的阅读。 此外浏览器其实原生也提供了如何解压和压缩文件的API,但是浏览器提供的这个API可能使用上并不是非常的友好,需要对流有一定的理解才能得心应手。因此我推荐大家使用JSZip,它可以很方便的压缩和解压缩一个文件,并且在浏览器和Nodejs这两个运行时中都支持。接下来我们来看一下它的使用方法,以下是一个压缩和解压缩的还原字符串的案例。 <html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>JSZip Demo</title>
<script src="https://cdnjs.cloudflare.com/ajax/libs/jszip/3.1.5/jszip.min.js"></script>
</head>
<body>
<script>
// 压缩字符串
function compressString(originalString) {
return new Promise((resolve, reject) => {
const zip = new JSZip();
zip.file("compressed.txt", originalString);
zip
.generateAsync({ type: "blob" })
.then((compressedBlob) => {
const reader = new FileReader();
reader.onload = () => resolve(reader.result);
reader.readAsText(compressedBlob);
})
.catch(reject);
});
}
// 解压缩字符串
function decompressString(compressedString) {
return new Promise((resolve, reject) => {
const zip = new JSZip();
zip
.loadAsync(compressedString)
.then((zipFile) => {
const compressedData = zipFile.file("compressed.txt");
// debugger;
if (compressedData) {
return compressedData.async("string");
} else {
reject(
new Error("Unable to find compressed data in the zip file.")
);
}
})
.then(resolve)
.catch(reject);
});
}
// 示例
const originalText =
"Hello, this is a sample text for compression and decompression with JSZip.";
console.log("Original Text:", originalText);
// 压缩字符串
compressString(originalText)
.then((compressedData) => {
console.log("Compressed Data:", compressedData);
// 解压字符串
decompressString(compressedData)
.then((decompressedText) => {
console.log("Decompressed Text:", decompressedText);
})
.catch((error) => {
console.error("Error during decompression:", error);
});
})
.catch((error) => {
console.error("Error during compression:", error);
});
</script>
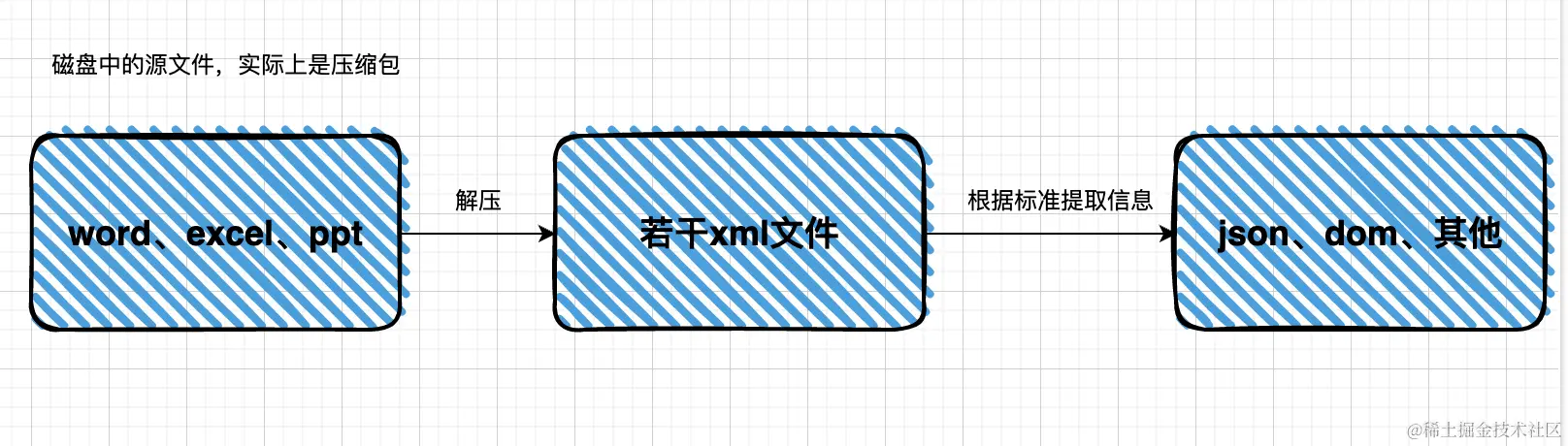
</body></html> 当我们的办公文件(excel、word、ppt)解压缩之后就变成一堆xml文件了,然后在浏览器端可以通过前面小节提到的解析过程进行解析,可以把数据提取出来生成json,也可以创建为DOM,这个就由开发者自己选择了。 因此主流的第三方库解析路径如下图所示:
当然这个解析过程其实并不难,关键在于这些第三方库将依据
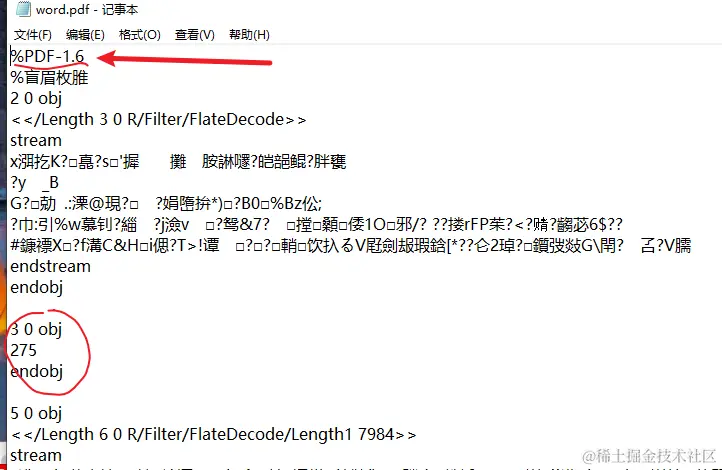
三、PDF前面的文章都是提到的办公文件,也就是excel、word、ppt这些文件,但我们一字未提PDF。 那么PDF和这些文件有何不同呢?我们先从它为什么被大家使用谈起,大家可能有这样的体会,当你使用word文档软件写好了一篇论文之后,就会拿到打印店去打印,结果用打印店的软件一打开,发现辛辛苦苦排版好的内容全都乱了,虽然也没有特别丑,但是和你之前排版的完全不一样。 这个时候你的好室友就会建议你先将这份word文档转换为PDF格式,然后再去打印,结果会发现PDF无论在哪里打开,它几乎都是一模一样的,排版和导出时候的样子都是一样的。 本质PDF对应的就是电子世界的打印纸张,它拥有不可编辑、占用空间小、稳定性强、可加密等特点,它由Adobe于1993年首次提出,旨在实现跨平台和可靠性的文档显示。PDF文件可以包含文本、图形、图像和其他多媒体元素,并以一种独立于操作系统和硬件的方式呈现。 我们前面说到办公软件的本质其实是压缩包,那么PDF是压缩包么? 虽然PDF存储空间小,感觉很像个压缩包,但其实还真不是,PDF的文件可以直接使用文本编辑器强行打开,打开之后可以看到一些似乎有意义的数据。
可以看到第一行有一个PDF-1.6,它其实表明了应该使用pdf1.6版本的规范去解析这份文档,下面还有一些数字信息描述的其实是坐标相关的信息。 你也可以新建一个文本,把下面这段字符串粘贴其中,把后缀名改成**.pdf**,就会惊奇的发现你居然手写了一个PDF出来。 %PDF-1.1
%¥±ë
1 0 obj
<< /Type /Catalog
/Pages 2 0 R
>>
endobj
2 0 obj
<< /Type /Pages
/Kids [3 0 R]
/Count 1
/MediaBox [0 0 300 144]
>>
endobj
3 0 obj
<< /Type /Page
/Parent 2 0 R
/Resources
<< /Font
<< /F1
<< /Type /Font
/Subtype /Type1
/BaseFont /Times-Roman
>>
>>
>>
/Contents 4 0 R
>>
endobj
4 0 obj
<< /Length 55 >>
stream
BT
/F1 18 Tf
0 0 Td
(Hello World) Tj
ET
endstream
endobj
xref
0 5
0000000000 65535 f
0000000018 00000 n
0000000077 00000 n
0000000178 00000 n
0000000457 00000 n
trailer
<< /Root 1 0 R
/Size 5
>>
startxref
565
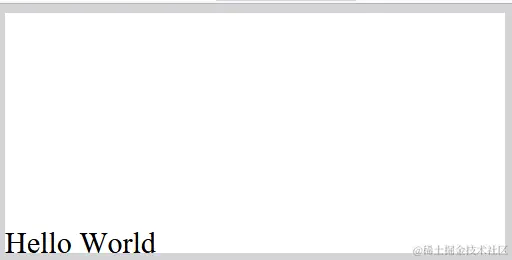
%%EOF 打开预览如图所示:
如果把PDF的语言翻译成人话大概是下面这个样子。 【文字开始】
缩放比例1倍 坐标(1036,572) 【文字定位】
/TT1 12磅 【选择字体】
[ (He) 间距24 (l) 间距-48 (l) 间距-48 (o) ] 【绘制文字】
【文字结束】
【文字开始】
缩放比例1倍 坐标(1147,572) 【文字定位】
/TT1 12磅 【选择字体】
(空格) 【绘制文字】
【文字结束】
【文字开始】
缩放比例1倍 坐标(1060,572) 【文字定位】
/TT1 12磅 【选择字体】
[ (w) 间距24 (or) 间距-84 (l) 间距-24 (d) ] 【绘制文字】
【文字结束】 可以看到,PDF有一套自己的语法规则,这套规则描述了一张固定大小的纸张上哪个文字应该放在哪个位置,这个信息是绝对的。如果对比上面的word文档,他们描述信息的方式采用的是xml,xml只是存储了信息,但是这些信息的具体排布方式是由各自的软件决定的,我们举个简单的例子方便大家理解。 假设有一个段落存储了 在word里xml的描述很可能是这样的 这段信息在微软里面可能占1行,在WPS中很可能占2行,因为这个xml并没有描述应该占几行这样的信息,所以留给各家软件在排版上的自由度还是比较高的。 但是在pdf中,可能就有以下的描述: 【文字开始】
颜色#000 坐标(0,0)
字号14【大家好,我是一串文字】
【文字结束】
翻译以下就是:引擎你在画板0,0位置给我画个"大",在0,1位置给我画个"家"... PDF中是描述了文字的布局信息,相当于一个指针告诉解析器应该在哪个位置画一个怎样的符号。 这样绝对的信息让得到这份文件的人可以在一个指定大小的空间每次都画出一模一样的内容来,因此是绝对稳定的。 如果需要实现一个PDF解析器,则需要对PDF使用的这套规则语法有深入的了解,因为这套规则就是一门语言,并且是图灵完备的,所以要实现能够解析它的引擎,并不比实现一个V8简单多少,幸好几乎现代浏览器都支持解析PDF。并且提供了强大的功能。 我们可以选择使用embed标签或者iframe标签来解析PDF。 <embed src="example.pdf" width="800px" height="600px" type="application/pdf"> <!-- 或 --> <iframe src="example.pdf" width="800px" height="600px"></iframe> 或者如果希望将PDF完全由DOM来渲染,则可以使用mozilla开源的pdf.js。
参考资料www.ruanyifeng.com/blog/2007/1… 维护维护于2023.12.19,有小伙伴建议把延伸阅读的文章总结一下,这就给各位整理一下: IT历史连载30-office办公软件的历史 转自https://juejin.cn/post/7313048171797544997 该文章在 2024/11/2 10:31:38 编辑过 |
关键字查询
相关文章
正在查询... 



|


 400 186 1886
400 186 1886