窗口函数(Window Function)是 MySQL 8.0 新增的一个重要的功能,可以为数据分析提供强大的支持,例如计算分组排名、累积求和、同比/环比增长率等。本篇我们就来了解一下 MySQL 中窗口函数的语法和各种窗口函数的作用。
另外,这里有一份 SQL 窗口函数速查表;欢迎下载保存,以便不时之需。
22.1 窗口函数概述
在第 12 篇中我们学习了常见的聚合函数,包括 AVG、COUNT、MAX、MIN、SUM 以及 GROUP_CONCAT。聚合函数的作用就是对一组数据行进行汇总计算,并且返回单个分析结果。
窗口函数和聚合函数类似之处在于它也是对一组数据进行分析;但是,窗口函数不是将一组数据汇总为单个结果;而是针对查询中的每一行数据,基于和它相关的一组数据计算出一个结果。下图演示了聚合函数和窗口函数的区别:

📝窗口函数在其他数据库中也叫做分析函数(Analytic Function),或者联机分析处理(OLAP)函数。
为了便于理解,我们可以比较一下聚合函数和窗口函数的结果。以下示例分别将 COUNT 作为聚合函数和窗口函数,计算员工的人数:
SELECT count(*)
FROM employee;
count(*)|
--------|
25|
SELECT emp_id, emp_name, count(*) OVER ()
FROM employee;
emp_id|emp_name |count(*) OVER ()|
------|---------|----------------|
13|关兴 | 25|
11|关平 | 25|
2|关羽 | 25|
1|刘备 | 25|
16|周仓 | 25|
8|孙丫鬟 | 25|
...
聚合函数(COUNT(*))通常也可以作为窗口函数(COUNT(*) OVER()),区别在于后者包含了OVER关键字;空括号表示将所有数据作为整体进行分析,所以得到的数值和聚合函数一样。查询结果中,聚合函数只返回了一个汇总结果,而窗口函数为每一个员工都返回了一个结果。
22.2 窗口函数的定义
窗口函数与其他函数的语法区别主要在于OVER子句,接下来我们介绍它的语法。窗口函数的定义如下:
window_function ( expr ) OVER (
PARTITION BY ...
ORDER BY ...
frame_clause
)
其中,window_function 是窗口函数的名称;expr 是参数,有些函数不需要参数;OVER子句包含三个选项:分区(PARTITION BY)、排序(ORDER BY)以及窗口大小(frame_clause)。
22.2.1 分区选项(PARTITION BY)
PARTITION BY选项用于将数据行拆分成多个分区(组),窗口函数基于每一行数据所在的组进行计算并返回结果,它的作用类似于GROUP BY分组。如果省略了 PARTITION BY,所有的数据作为一个组进行计算,上文中的示例就是如此。
以下示例按照不同的部门分别统计员工的月薪合计:
SELECT emp_name "姓名", salary "月薪", dept_id "部门编号",
sum(salary) OVER (PARTITION BY dept_id) AS "部门月薪合计"
FROM employee;
其中,OVER 子句中的 PARTITION BY 选项表示按照部门进行分区;因此,SUM 函数按照部门分别统计月薪的合计值。该语句的结果如下(只显示了前 3 个部门的结果):
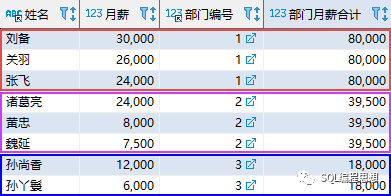
前 3 行数据的部门编号都为 1,因此该部门的月薪合计为 30000 + 26000 + 24000 = 80000;其他部门的数据也采用同样的方式进行计算。
📝SQL 标准要求 PARTITION BY 之后只能使用字段名,不过 MySQL 允许指定表达式。另外,我们也可以在 PARTITION BY 之后指定多个分组字段,例如同时按照部门和性别进行分组分析。
22.2.2 排序选项(ORDER BY)
OVER 子句中的ORDER BY选项用于指定分区内的排序方式,与 ORDER BY 子句的作用类似,通常用于数据的排名分析。以下示例用于计算每个员工在部门内的月薪排名:
SELECT emp_name "姓名", salary "月薪", dept_id "部门编号",
rank() OVER (
PARTITION BY dept_id
ORDER BY salary DESC
) AS "部门排名"
FROM employee;
其中,PARTITION BY 选项表示按照部门进行分区;ORDER BY 选项指定在分区内按照月薪从高到低进行排序;RANK 函数用于计算名次,该函数将会在下文中进行介绍。
该语句的结果如下(只显示了前 3 个部门的结果):
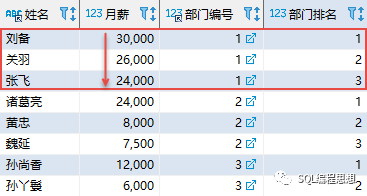
前 3 行数据的部门编号都为 1;“刘备”的月薪最高,在部门内排名第一;“关羽”排名第二;“张飞”排名第三。其他部门的数据采用同样的方式进行计算。
📝ORDER BY 选项用于指定分区内数据的排序,排序字段数据相同的行是对等行(peer)。如果省略 ORDER BY ,分区内的数据不进行排序,不按照固定顺序处理, 而且所有数据都是对等行。
22.2.3 窗口选项(frame_clause)
frame_clause选项用于在当前分区内指定一个计算窗口,也就是一个与当前行相关的数据子集。指定了窗口之后,分析函数不再基于分区进行计算,而是基于窗口内的数据进行计算。窗口会随着当前处理的数据行而移动,例如:
{ ROWS | RANGE } frame_start
{ ROWS | RANGE } BETWEEN frame_start AND frame_end
其中,ROWS表示以行为单位指定窗口的偏移量,RANGE表示以数值(例如 30 分钟)为单位指定窗口的偏移量。frame_start 和 frame_end 分别表示窗口的开始行和结束行,它们的可能取值如下:
CURRENT ROW
UNBOUNDED PRECEDING
UNBOUNDED FOLLOWING
expr PRECEDING
expr FOLLOWING
frame_start 和 frame_end 的具体意义如下:
CURRENT ROW:对于 ROWS 方式,代表了当前行;对于 RANGE,代表了当前行的所有对等行。
UNBOUNDED PRECEDING:代表了分区中的第一行。
UNBOUNDED FOLLOWING:代表了分区中的最后一行。
expr PRECEDING:对于 ROWS 方式,代表了当前行之前的第 expr 行;对于 RANGE,代表了等于当前行的值减去 expr 的所有行;如果当前行的值为 NULL,代表了当前行的所有对等行。
expr FOLLOWING:对于 ROWS 方式,代表了当前行之后的第 expr 行;对于 RANGE,代表了等于当前行的值加上 expr 的所有行;如果当前行的值为 NULL,代表了当前行的所有对等行。
如果只有 frame_start,默认以当前行作为窗口的结束。如果同时指定了两者,frame_start 不能晚于 frame_end,例如 BETWEEN 1 FOLLOWING AND 1 PRECEDING 就是一个无效的窗口。下图可以方便我们理解这些选项的含义:
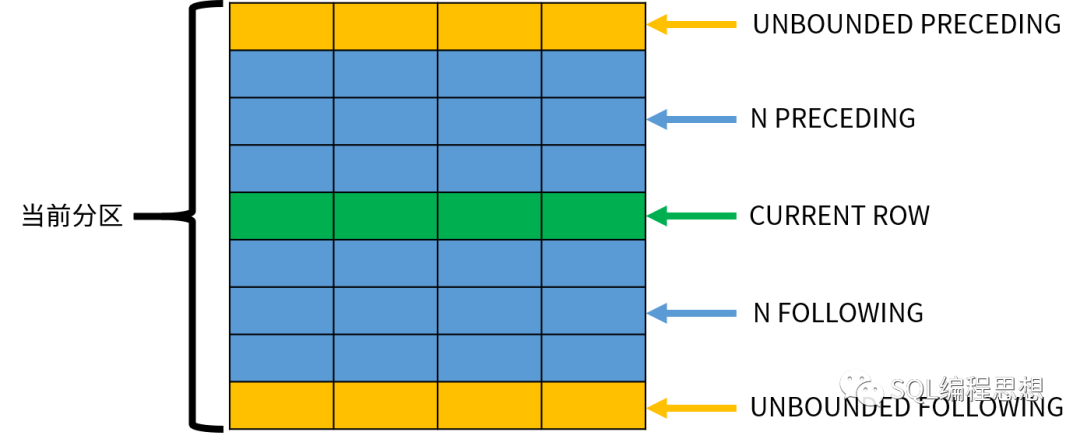
CURRENT ROW表示当前正在处理的行;其他的行可以使用相对当前行的位置表示。需要注意,窗口的大小不会超出当前分区的范围。
以下示例按照部门统计员工的累计月薪值:
SELECT d.dept_name "部门名称", e.emp_name "姓名", e.salary "月薪",
sum(salary) OVER (
PARTITION BY e.dept_id
ORDER BY e.emp_id
ROWS UNBOUNDED PRECEDING
) AS "部门累计月薪"
FROM employee e
JOIN department d ON (e.dept_id = d.dept_id);
其中,PARTITION BY 选项表示按照部门进行分区;ORDER BY 选项表示按照工号进行排序;窗口子句 ROWS UNBOUNDED PRECEDING 指定窗口从分区的第一行开始,默认到当前行结束;因此 SUM 函数计算的是部门内累计到当前员工为止的月薪合计。该查询的结果如下(只显示了前 3 个部门的结果):
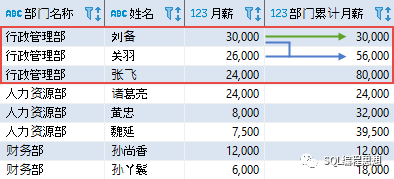
对于“行政管理部”,第一个员工的月薪为 30000,累计也是 30000;第二个员工的月薪为 26000,累计为 30000 + 26000 = 56000;依此类推,直到统计完该部门的所有员工;然后开始统计下一个部门的数据。
22.2.4 命名窗口
窗口函数的 OVER 子句除了直接定义三种选项之外,还可以使用一个预定义的窗口变量进行定义。窗口变量使用WINDOW子句进行定义,语法位于 HAVING 和 ORDER BY 之间。
window_function(expr) OVER window_name
WINDOW window_name AS (PARTITION BY ... ORDER BY ... frame_clause)
WINDOW window_name AS (other_window_name)
如果查询中多个窗口函数的 OVER 子句相同,利用 WINDOW 子句定义一个窗口变量,然后在多个 OVER 子句中使用该变量可以简化查询语句。例如:
SELECT d.dept_name "部门名称", e.emp_name "姓名", e.salary "月薪",
sum(salary) OVER w AS "部门累计月薪",
count(*) OVER w AS "部门累计人数"
FROM employee e
JOIN department d ON (e.dept_id = d.dept_id)
WINDOW w AS (
PARTITION BY e.dept_id
ORDER BY e.emp_id
ROWS UNBOUNDED PRECEDING
);
接下来我们介绍一些常见的窗口函数和示例。
22.3 常用窗口函数
常见的窗口函数可以分为以下几类:聚合窗口函数、排名窗口函数以及取值窗口函数。
📝窗口函数只能出现在 SELECT 列表和 ORDER BY 子句中,查询语句的处理顺序依次为 FROM、WHERE、GROUP BY、聚合函数、HAVING、窗口函数、SELECT DISTINCT、ORDER BY、LIMIT。
22.3.1 聚合窗口函数
常用的聚合函数,例如 AVG、SUM、COUNT 等,也可以作为窗口函数使用。上文我们已经列举了一些聚合窗口函数的示例,再来看一个使用 AVG 函数计算移动平均值的例子:
SELECT d.dept_name "部门名称", e.emp_name "姓名", e.salary "月薪",
avg(salary) OVER (
PARTITION BY e.dept_id
ORDER BY e.salary
ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING
) AS "移动平均月薪"
FROM employee e
JOIN department d ON (e.dept_id = d.dept_id);
部门名称 |姓名 |月薪 |移动平均月薪 |
--------|------|--------|------------|
行政管理部|张飞 |24000.00|25000.000000|
行政管理部|关羽 |26000.00|26666.666667|
行政管理部|刘备 |30000.00|28000.000000|
人力资源部|魏延 | 8000.00| 8250.000000|
人力资源部|黄忠 | 8500.00|13833.333333|
人力资源部|诸葛亮|25000.00|16750.000000|
...
其中,PARTITION BY 选项表示按照部门进行分区;ORDER BY 选项表示按照月薪从低到高进行排序;窗口子句 ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING 指定窗口从当前行的前一行开始,到当前行的下一行结束;因此该函数计算的是每个部门内员工与其前后各一个员工的平均月薪值。
移动平均值通常用于处理时间序列的数据。例如,厂房的温度检测器获取了每秒钟的温度,我们可以使用以下窗口计算前五分钟内的平均温度:
avg(temperature) OVER (ORDER BY ts RANGE BETWEEN interval '5 minute' PRECEDING AND CURRENT ROW)
22.3.2 排名窗口函数
排名窗口函数用于对数据进行分组排名。常见的排名窗口函数包括:
ROW_NUMBER,为分区中的每行数据分配一个序列号,序列号从 1 开始分配。
RANK,计算每行数据在其分区中的名次;如果存在名次相同的数据,后续的排名将会产生跳跃。
DENSE_RANK,计算每行数据在其分区中的名次;即使存在名次相同的数据,后续的排名也是连续的值。
PERCENT_RANK,以百分比的形式显示每行数据在其分区中的名次;如果存在名次相同的数据,后续的排名将会产生跳跃。
CUME_DIST,计算每行数据在其分区内的累积分布,也就是该行数据及其之前的数据的比率;取值范围大于 0 并且小于等于 1。
NTILE,将分区内的数据分为 N 等份,为每行数据计算其所在的位置。
排名窗口函数不支持动态的窗口大小(frame_clause),而是以当前分区作为分析的窗口。以下示例按照部门分组,并计算每个员工在其部门中的月薪排名,分别使用了 4 个不同的排名函数:
SELECT d.dept_name "部门名称", e.emp_name "姓名", e.salary "月薪",
ROW_NUMBER() OVER (PARTITION BY e.dept_id ORDER BY e.salary DESC) AS "row_number",
RANK() OVER (PARTITION BY e.dept_id ORDER BY e.salary DESC) AS "rank",
DENSE_RANK() OVER (PARTITION BY e.dept_id ORDER BY e.salary DESC) AS "dense_rank",
PERCENT_RANK() OVER (PARTITION BY e.dept_id ORDER BY e.salary DESC) AS "percent_rank"
FROM employee e
JOIN department d ON (e.dept_id = d.dept_id);
部门名称 |姓名 |月薪 |row_number|rank|dense_rank|percent_rank |
--------|-----|--------|----------|----|----------|-------------------|
行政管理部|刘备 |30000.00| 1| 1| 1| 0.0|
行政管理部|关羽 |26000.00| 2| 2| 2| 0.5|
行政管理部|张飞 |24000.00| 3| 3| 3| 1.0|
...
研发部 |赵云 |15000.00| 1| 1| 1| 0.0|
研发部 |周仓 | 8000.00| 2| 2| 2| 0.125|
研发部 |关兴 | 7000.00| 3| 3| 3| 0.25|
研发部 |关平 | 6800.00| 4| 4| 4| 0.375|
研发部 |赵氏 | 6600.00| 5| 5| 5| 0.5|
研发部 |廖化 | 6500.00| 6| 6| 6| 0.625|
研发部 |张苞 | 6500.00| 7| 6| 6| 0.625|
研发部 |赵统 | 6000.00| 8| 8| 7| 0.875|
研发部 |马岱 | 5800.00| 9| 9| 8| 1.0|
...
其中,4 个函数的 OVER 子句完全相同;PARTITION BY 表示按照部门进行分区;ORDER BY 表示按照月薪从高到低进行排序。我们以结果中的“研发部”为例进行分析:
ROW_NUMBER 函数为每个员工分配了一个连续的数字编号,可以看作是一种排名。其中“廖化”和“张苞”的月薪相同,但是编号不同;
RANK 函数为每个员工指定了一个名次,其中“廖化”和“张苞”的名次都是 6。在他们之后的“赵统”的名次为 8,产生了跳跃;
DENSE_RANK 函数为每个员工指定了一个名次,其中“廖化”和“张苞”的名次都是 6。在他们之后的“赵统”的名次为 7,名次是连续值;
PERCENT_RANK 函数按照百分比指定名次,取值位于 0 到 1 之间。其中“赵统”的百分比排名为 0.875,也产生了跳跃。
以下语句演示了 CUME_DIST 和 NTILE 函数的作用:
SELECT emp_name AS "姓名", salary AS "月薪",
CUME_DIST() OVER (ORDER BY salary DESC) AS "累积占比",
NTILE(5) OVER (ORDER BY salary DESC) AS "相对位置"
FROM employee;
姓名 |月薪 |累积占比|相对位置|
-----|--------|------|----|
刘备 |30000.00| 0.04| 1|
关羽 |26000.00| 0.08| 1|
诸葛亮|25000.00| 0.12| 1|
张飞 |24000.00| 0.16| 1|
赵云 |15000.00| 0.2| 1|
孙尚香|12000.00| 0.24| 2|
...
糜竺 | 4300.00| 0.84| 5|
黄权 | 4200.00| 0.88| 5|
庞统 | 4100.00| 0.92| 5|
蒋琬 | 4000.00| 1.0| 5|
邓芝 | 4000.00| 1.0| 5|
其中,OVER 子句没有指定分区选项,因此所有的员工作为一个整体进行分析;ORDER BY 按照月薪从高到低进行排序。从结果可以看出,20% 的员工月薪大于等于 15000;或者说,月薪 15000 意味着在公司中的排名属于最高的 20%。NTILE 将员工按照月薪从高到低分成了 5 个组,相对位置为 1 的员工是月薪最高的 20% 员工。
22.3.3 取值窗口函数
取值窗口函数用于返回指定位置上的数据。常见的取值窗口函数包括:
FIRST_VALUE,返回窗口内第一行的数据。
LAST_VALUE,返回窗口内最后一行的数据。
NTH_VALUE,返回窗口内第 N 行的数据。
LAG,返回分区中当前行之前的第 N 行的数据。
LEAD,返回分区中当前行之后第 N 行的数据。
其中,LAG 和 LEAD 函数不支持动态的窗口大小(frame_clause),而是以当前分区作为分析的窗口。
以下语句使用 FIRST_VALUE、LAST_VALUE 以及 NTH 函数分别获取每个部门内部月薪最高、月薪最低以及月薪第二高的员工:
SELECT d.dept_name "部门名称", e.emp_name "姓名", e.salary "月薪",
first_value(salary) OVER w "最高月薪",
last_value(salary) OVER w "最低月薪",
nth_value(salary, 2) OVER w "第二高月薪"
FROM employee e
JOIN department d ON (e.dept_id = d.dept_id)
WINDOW w AS (
PARTITION BY e.dept_id
ORDER BY salary DESC
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING)
ORDER BY e.dept_id, salary DESC;
部门名称 |姓名 |月薪 |最高月薪 |最低月薪 |第二高月薪|
--------|-----|--------|--------|--------|--------|
行政管理部|刘备 |30000.00|30000.00|24000.00|26000.00|
行政管理部|关羽 |26000.00|30000.00|24000.00|26000.00|
行政管理部|张飞 |24000.00|30000.00|24000.00|26000.00|
人力资源部|诸葛亮|25000.00|25000.00| 8000.00| 8500.00|
人力资源部|黄忠 | 8500.00|25000.00| 8000.00| 8500.00|
人力资源部|魏延 | 8000.00|25000.00| 8000.00| 8500.00|
...
以上三个函数的默认窗口是从当前分区的第一行到当前行,所以我们在OVER子句中将窗口设置为整个分区。
LAG 和 LEAD 函数可以用于计算销量数据的环比/同比增长。我们创建一个新的数据表:sales_monthly,它记录了不同产品按月统计的销售金额。以下语句统计不同产品每个月的环比增长率:
SELECT product AS "产品", ym "年月", amount "销量",
(amount - LAG(amount, 1) OVER (PARTITION BY product ORDER BY ym))/
LAG(amount, 1) OVER (PARTITION BY product ORDER BY ym) * 100 AS "环比增长率(%)"
FROM sales_monthly
ORDER BY product, ym;
产品|年月 |销量 |环比增长率(%)|
---|------|--------|---------|
桔子|201801|10154.00| |
桔子|201802|10183.00| 0.285602|
桔子|201803|10245.00| 0.608858|
桔子|201804|10325.00| 0.780869|
桔子|201805|10465.00| 1.355932|
桔子|201806|10505.00| 0.382226|
桔子|201807|10578.00| 0.694907|
桔子|201808|10680.00| 0.964265|
桔子|201809|10788.00| 1.011236|
桔子|201810|10838.00| 0.463478|
桔子|201811|10942.00| 0.959587|
桔子|201812|10988.00| 0.420398|
桔子|201901|11099.00| 1.010193|
桔子|201902|11181.00| 0.738805|
桔子|201903|11302.00| 1.082193|
桔子|201904|11327.00| 0.221200|
桔子|201905|11423.00| 0.847532|
桔子|201906|11524.00| 0.884181|
...
其中,LAG(amount, 1) 表示获取上一期的销量;PARTITION BY 表示按照产品分区;ORDER BY 表示按照月份进行排序;当前月份的销量减去上个月的销量,再除以上个月的销量,就是环比增长率。
💡想一想,怎么计算同比增长率呢?同比增长是指本期数据与上一年度或历史同期相比的增长。例如,2019 年 6 月的销量与 2018 年 6 月的销量相比增加的部分。
该文章在 2024/3/15 15:03:08 编辑过






 400 186 1886
400 186 1886


