当面试官询问你如何在SQL中去除重复的记录,只保留独一无二的值时,你是否只能想到使用DISTINCT关键字呢?别担心,今天,我将分享给你6种去重方法,让你在面试中脱颖而出。毕竟,只有一个DISTINCT也太单调了嘛!
首先,我们创建2个表并插入些数据,用于演示去重方法。
-- 创建员工表
CREATE TABLE `employees` (
`emp_id` INT ( 11 ) NOT NULL AUTO_INCREMENT,-- 员工ID,主键,自增
`name` VARCHAR ( 60 ) NOT NULL COMMENT '员工名字',
`position` VARCHAR ( 100 ) DEFAULT NULL COMMENT '员工职位',
`department` VARCHAR ( 100 ) DEFAULT NULL COMMENT '员工所属部门',
`age` INT(3) COMMENT '员工年龄',
`hire_date` DATE DEFAULT NULL COMMENT '入职日期',
`birth_date` DATE DEFAULT NULL COMMENT '出生日期',
`address` VARCHAR ( 255 ) DEFAULT NULL COMMENT '家庭住址',
`gmt_create` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`gmt_modified` DATETIME DEFAULT NULL COMMENT '修改时间',
PRIMARY KEY ( `emp_id` ) -- 主键设置为员工ID
) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4 COMMENT = '员工信息表';-- 使用InnoDB引擎,字符集为utf8mb4,表注释为“员工信息表”
-- 创建员工工资表
CREATE TABLE `salaries` (
`salary_id` INT ( 11 ) NOT NULL AUTO_INCREMENT COMMENT '工资记录ID',-- 主键,自增
`emp_id` INT ( 11 ) NOT NULL COMMENT '员工ID',-- 外键,指向employees表
`name` VARCHAR ( 60 ) NOT NULL COMMENT '员工名字',
`salary_amount` DECIMAL ( 10, 2 ) NOT NULL COMMENT '工资总额',
`payment_date` DATE NOT NULL COMMENT '发放日期',
`deductions` DECIMAL ( 10, 2 ) DEFAULT '0.00' COMMENT '扣款金额',
`net_salary` DECIMAL ( 10, 2 ) DEFAULT '0.00' COMMENT '实发工资',
`gmt_create` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY ( `salary_id` ),
FOREIGN KEY ( `emp_id` ) REFERENCES `employees` ( `emp_id` ) -- 外键约束,确保员工ID在employees表中存在
) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4 COMMENT = '员工工资信息表';
-- 插入员工数据
INSERT INTO `employees` (`name`, `position`, `department`, `age`, `hire_date`, `birth_date`, `address`, `gmt_create`, `gmt_modified`) VALUES
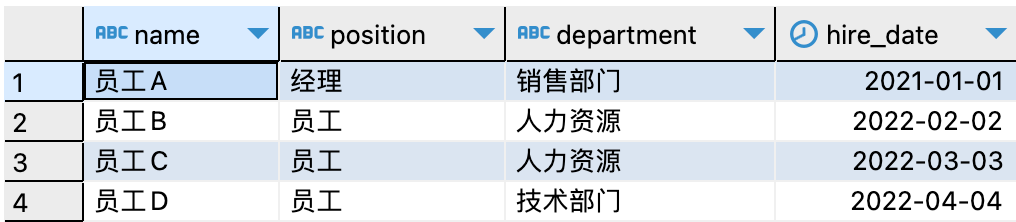
('员工A', '经理', '销售部门', '35', '2021-01-01', '1990-01-01', '北京', NOW(), NULL),
('员工B', '员工', '人力资源', '25', '2022-02-02', '1992-02-02', '广东', NOW(), NULL),
('员工C', '员工', '人力资源', '22', '2022-03-03', '1999-03-03', '上海', NOW(), NULL),
('员工D', '员工', '技术部门', '35', '2022-04-04', '1998-04-04', '山东', NOW(), NULL),
('员工D', '员工', '技术部门', '35', '2022-04-04', '1998-03-04', '上海', NOW(), NULL);
-- 插入工资数据
INSERT INTO `salaries` (`emp_id`, `name`, `salary_amount`, `payment_date`, `deductions`, `net_salary`, `gmt_create`) VALUES
(1, '员工A', 9000.00, '2023-06-30', 500.00, 8500.00, NOW()),
(2, '员工B', 4500.00, '2023-07-01', 450.00, 4050.00, NOW()),
(3, '员工C', 5900.00, '2023-06-30', 100.00, 5800.00, NOW()),
(4, '员工D', 8300.00, '2023-07-01', 200.00, 8100.00, NOW()),
(5, '员工D', 8300.00, '2023-06-30', NULL, NULL, NOW());
其中,employees表查询结果如下:
salaries表查询结果如下:
01.
使用DISTINCT关键字去重
DISTINCT关键字是SQL中常用的去重工具。当我们使用它时,后面需明确指定要去重的字段。这样,它将对指定的字段进行去重操作,并返回唯一的值。
1. 对单列数据去重
如果我们想要获取"employees"表中不重复的name字段,可以使用以下SQL语句:
SELECT DISTINCT `name` FROM employees
查询结果如下:
对单列使用distinct去除重复值时,会过滤掉多余重复相同的值,只返回唯一的值。
2. 对多列数据去重
如果需要对多列数据进行去重处理,只需在DISTINCT关键字后依次列出需要去重的字段名,并用英文逗号隔开即可。
例如,我们想要对"employees"表中name、position、department和hire_date字段去重,可以使用以下SQL语句。
SELECT DISTINCT `name`,`position`,department ,hire_date FROM employees
查询结果如下:
可以看到department的值是有重复的,这是因为DISTINCT其实是对后面所有列名的组合进行去重。也就是name+position+department+hire_date组合成的一行在整张表中都不重复的记录;在这里,因为name+position+department+hire_date有2个相同的数据,则过滤了一行。
使用DISTINCT关键字进行去重是相对简单的。然而,需要注意的是,DISTINCT关键字仅对指定的字段进行去重,如果需要返回其他字段的信息,这种方法可能会受到限制。
02.
使用GROUP BY子句去重
GROUP BY关键字是另一种常用的去重方法。它可以将相同的值分组,并只返回每组中的一个值。同时,它还可以返回其他字段信息,实现去重的同时提供更多相关信息。以下是GROUP BY子句的2种常见去重方法:
1. 对单列数据去重
如果我们想要获取"employees"表中不重复的name字段,可以使用以下SQL语句:
SELECT `name` FROM employees GROUP BY name
查询结果如下:
2. 对多列数据去重
倘若我们想要对"employees"表中name、position、department和hire_date字段去重,我们尝试使用GROUP BY子句如下:
SELECT `name`, `position`, `department`, `hire_date`
FROM employees
GROUP BY `name`
-- 执行结果如下
SQL 错误 [1055] [42000]: Expression #2 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'tb_users.employees.position' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with
在SQL 查询时,若是启用了only_full_group_by 规则,那么,当在 GROUP BY 子句中没有列出的字段,又在 SELECT 中出现且没有使用聚合函数,就会导致错误。简单来说,SELECT 中的字段要么是 GROUP BY 里的,要么就得用聚合函数处理,否则查询会失败。
正确语法如下:
SELECT `name`, `position`, `department`, `hire_date`
FROM employees
GROUP BY `name`, `position`, `department`, `hire_date`;
查询结果如下:
3. 结合聚合函数
如果我们不仅想对name字段去重,还想获取每个员工的最早出生日期,可以这样写:
SELECT name ,MIN(birth_date)
FROM employees e
GROUP BY e.name
查询结果如下:
这个查询返回了name字段的唯一值和与之相关的birth_date字段的最小值。
也就是说,我们可以使用GROUP BY返回分组字段或其他字段的聚合信息。
03.
使用NOT EXISTS子查询去重
NOT EXISTS是一种逻辑运算符,用于判断一个子查询是否返回结果。如果子查询没有返回结果,则返回TRUE;否则返回FALSE。我们可以利用这个特性来去除重复的记录。
倘若我们想要获取"employees"表中重复名字中第一个出现的员工,可以使用以下SQL语句:
SELECT
e.emp_id , e.name, e.birth_date
FROM
employees e
WHERE
NOT EXISTS (
SELECT
1
FROM
employees
WHERE
name = e.name
AND emp_id < e.emp_id
);
这个查询将返回employees表中emp_id, name和birth_date列,且排除其他员工名与当前员工相同,且他的emp_id小于当前员工的emp_id。换句话说,将返回重复名字中emp_id最小的那个员工信息。
查询结果如下:
04.
使用LAG和LEAD函数去重
在SQL中,LAG和LEAD函数允许我们访问结果集中的前一行和后一行的数据,这在处理时间序列数据或比较当前行与相邻行数据时非常有用。我们可以巧妙地使用这些函数与其他SQL功能(如:GROUP BY、HAVING和DISTINCT) 结合起来实现去重的目的。
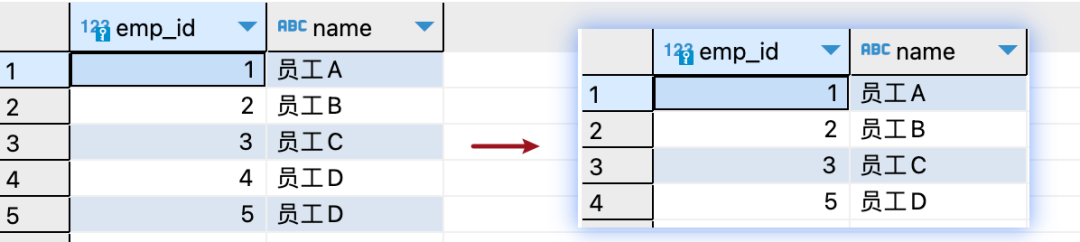
如果我们想要获取"employees"表中不重复的emp_id、name字段,可以使用以下SQL语句:
SELECT
DISTINCT emp_id,
name
FROM
(
SELECT
emp_id,
name,
LAG(name, 1, '') OVER (
order by emp_id ) AS prev_name
FROM
employees
) AS t
WHERE
prev_name IS NULL
OR prev_name <> name;
这个语句是从employees表中选择唯一的emp_id和name。内部查询使用LAG函数来获取每个emp_id的前一个name(按照emp_id排序),如果前一个name不存在,则默认为''(空字符串)。最后,在外部查询中,我们筛选出prev_name为NULL或者prev_name与当前name不相等的记录。这种方式可以找出名字在员工列表中发生变化的员工的emp_id和name。
查询结果如下:
若将上述SQL语句中的LAG函数替换为LEAD函数后,我们可以访问结果集中的后一行数据,而不是前一行数据。因此,执行结果将与原始SQL语句相反。
05.
使用IN去重
使用"IN"操作可以找到一组数据中不重复的特征,然后基于这些特征来获取数据。这样,我们能够更精确地筛选出具有特定属性的数据,确保数据的唯一性。
倘若我们想要获取"employees"表中具有相同名字的最大"emp_id"的员工信息,可以使用以下SQL语句:
select
e.emp_id ,
e.name,
e.birth_date
from
employees e
where
emp_id in (
select
max(emp_id)
from
employees
group by
name
);
查询结果如下:
可以看到返回了emp_id值为5的员工信息,而不是emp_id为4的员工信息。
然而,这种方法的可行性取决于表中是否存在一个唯一标识每条记录的字段,也就是,一个数据不重复的字段,例如employees表中的emp_id字段。若表中不存在此类字段,该方法则无法适用。
06.
使用UNION去重
UNION 是 SQL 中用于合并两个或多个 SELECT 语句的结果集的操作符。当使用 UNION 时,结果集会自动去重,即重复的行只会出现一次。这与INNER JOIN类似,都是求并集,但INNER JOIN是根据两个或多个表的共同列来合并数据,只返回匹配的行。
倘如,我们想要获取"employees"表中不重复的name字段,可以使用以下SQL语句:
SELECT `name` FROM employees
UNION
SELECT `name` FROM salaries;
这条语句会从 "employees" 表和 "salaries" 表中选取 "name" 字段,并通过 UNION 操作符合并结果集,确保结果中的 "name" 值是唯一的。
查询结果如下:
🌟 使用时需注意:
1、UNION联接的两个表必须具有相同的列名和数据类型,否则会报错。
2、UNION会去重,如需保留重复记录,可使用UNION ALL。若确定结果无重复或无需去重,建议使用UNION ALL以提高效率。
除了以上提到的方法,还有许多其他的去重技巧,比如:ROW_NUMBER()窗口函数、EXCEPT运算符、SET运算符,以及INNER JOIN结合GROUP BY等。
关于SQL中去重的方法,就分享到这了~
希望这个系列能帮助大家更深入地理解和运用数据库。
该文章在 2024/1/31 12:35:07 编辑过






 400 186 1886
400 186 1886