[点晴永久免费OA][转帖]浏览器工作原理
当前位置:点晴教程→点晴OA办公管理信息系统
→『 经验分享&问题答疑 』
有许多浏览器正在被使用,截至2022年,使用最多的是:谷歌浏览器、苹果的Safari、微软的Edge和火狐。 但是,它们实际上是如何工作的,从我们在地址栏中键入网络地址开始,到我们试图访问的页面显示在屏幕上,会发生什么? 关于这个问题的答案,一个极其简化的版本是:
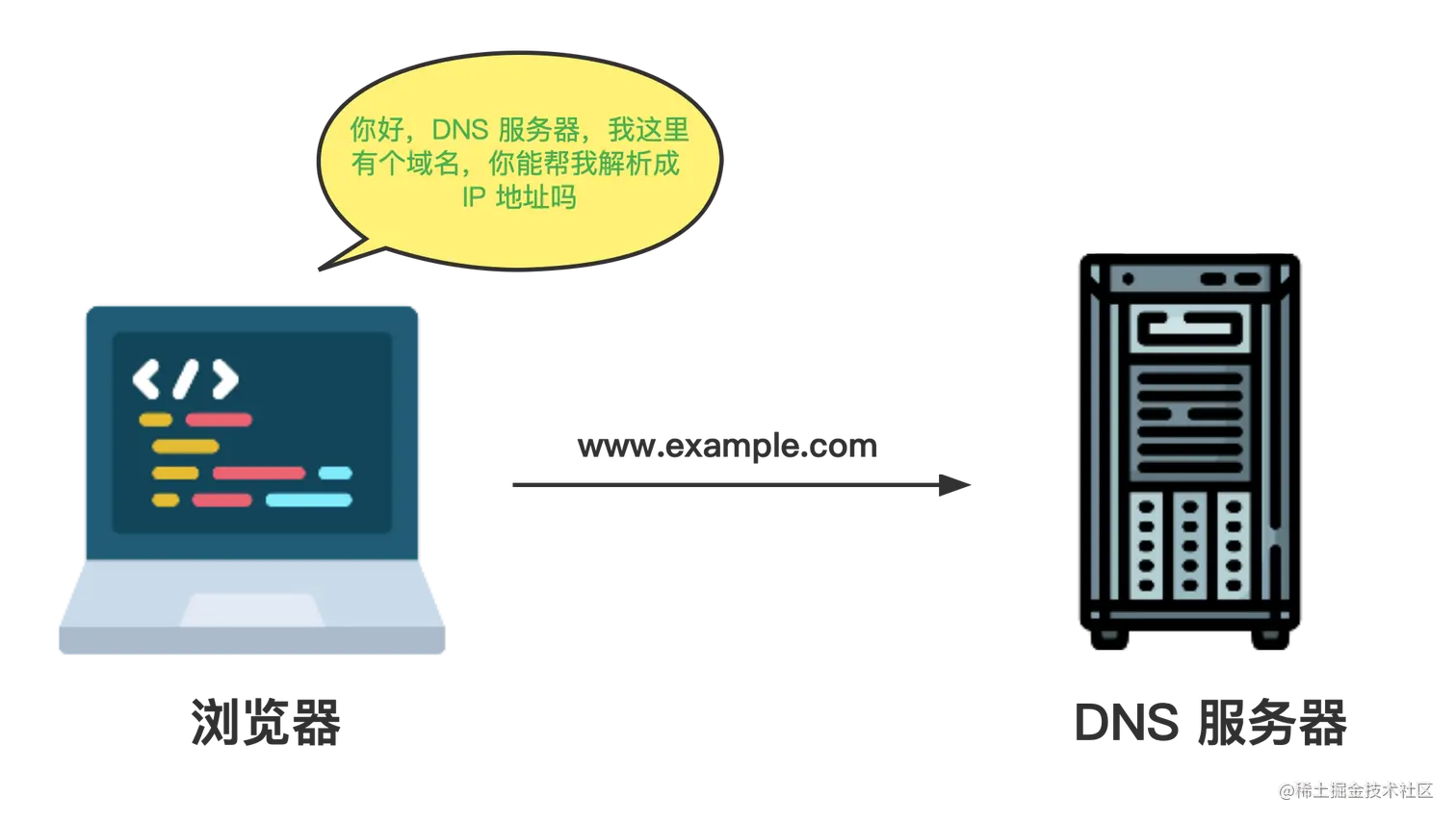
很直接,对吗?是的,但在这个看似超级简单的过程中还涉及更多的内容。在这个系列中,我们将讨论 1.导航导航是加载网页的第一步。它指的是当用户通过 DNS 查询(解决网址问题)导航到一个网页的第一步是找到该网页的静态资源位置(HTML、CSS、Javascript和其他类型的文件)。如果我们导航到 example.com ,HTML 页面位于 IP 地址为 93.184.216.34 的服务器上(对我们来说,网站是域名,但对计算机来说,它们是 IP 地址)。如果我们以前从未访问过这个网站,就必须进行域名系统(DNS)查询。
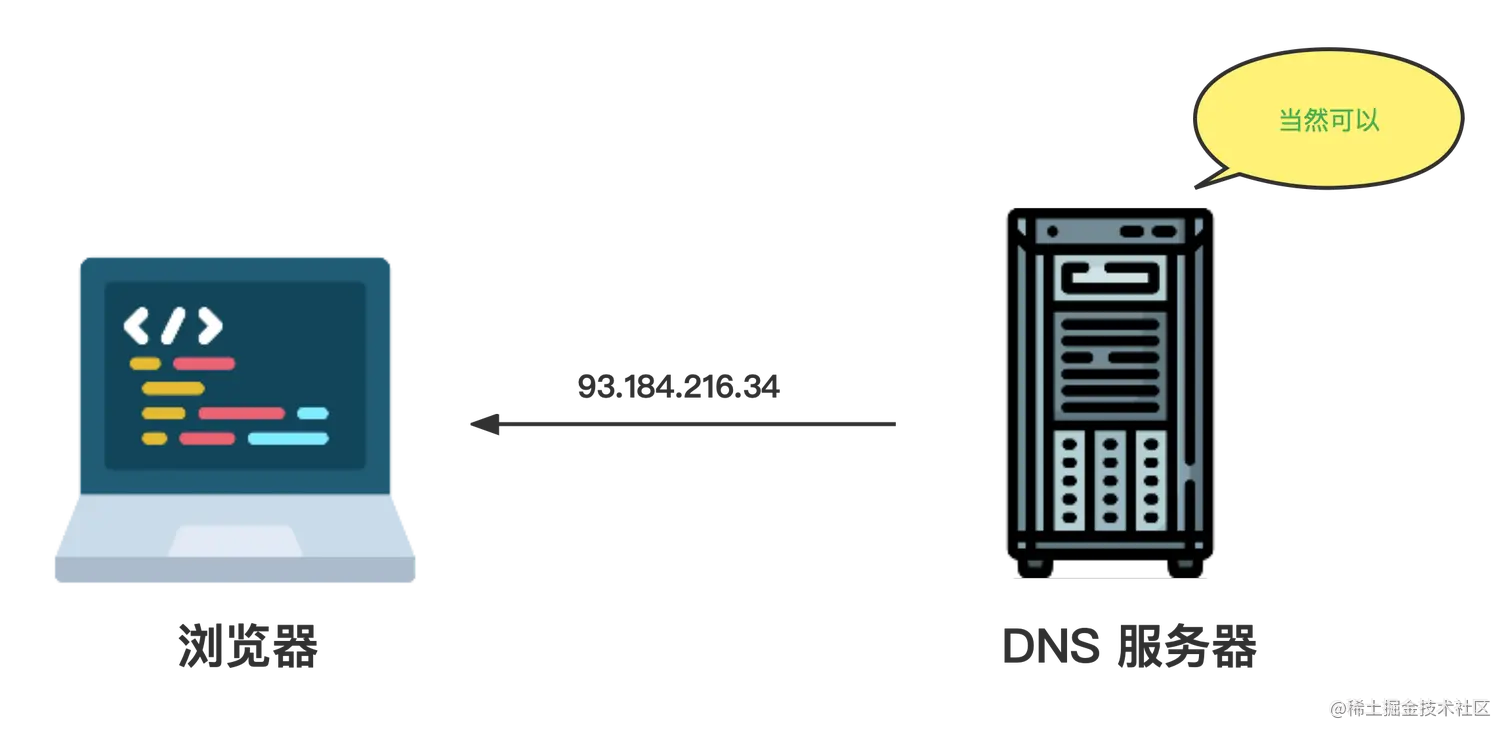
因此,当我们请求进行 DNS 查询时,我们实际做的是与这些服务器中的一个进行对话,要求找出与example.com 名称相对应的IP地址。如果找到了一个对应的 IP,就会返回。如果发生了一些情况,查找不成功,我们会在浏览器中看到一些错误信息。
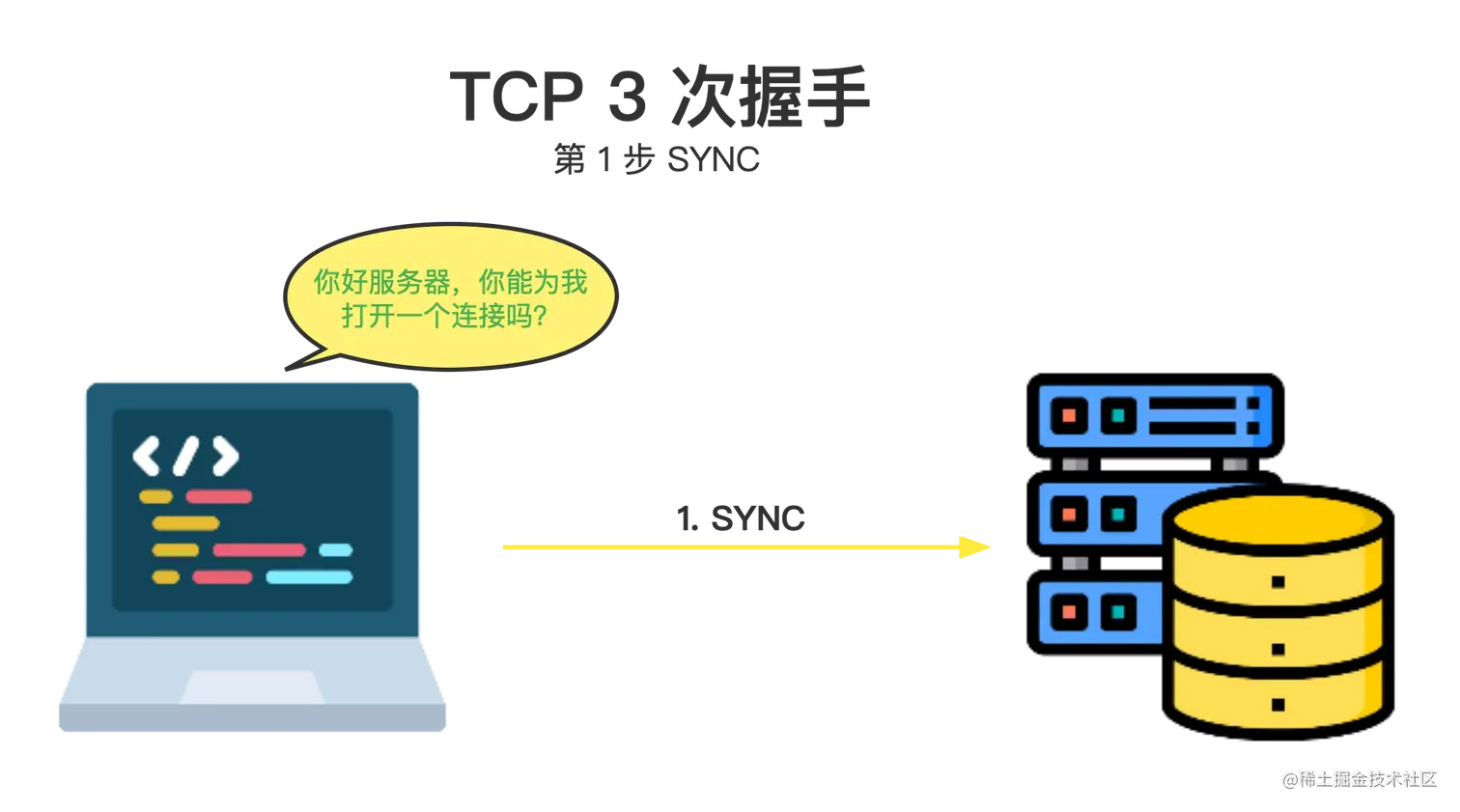
在这个最初的查询之后,IP 地址可能会被缓存一段时间,所以下次访问同一个网站会更快,因为不需要进行 DNS 查询(记住,DNS 查询只发生在我们第一次访问一个网站时)。 TCP (Transmission Control Protocol) 握手一旦浏览器知道了网站的 IP 地址,它将尝试通过 TCP 三次握手(也称为 SYN-SYN-ACK,或者更准确的说是 SYN、SYN-ACK、ACK,因为 TCP 有三个消息传输,用于协商和启动两台计算机之间的TCP 会话),与持有资源的服务器建立连接。
TCP 握手是一种机制,旨在让两个想要相互传递信息的实体(在我们的例子中是浏览器和服务器)在传输数据之前协商好连接的参数。 因此,如果浏览器和服务器是两个人,他们之间的对话会是这样的:
浏览器向服务器发送一个 SYNC 消息,要求进行同步(同步意味着连接)
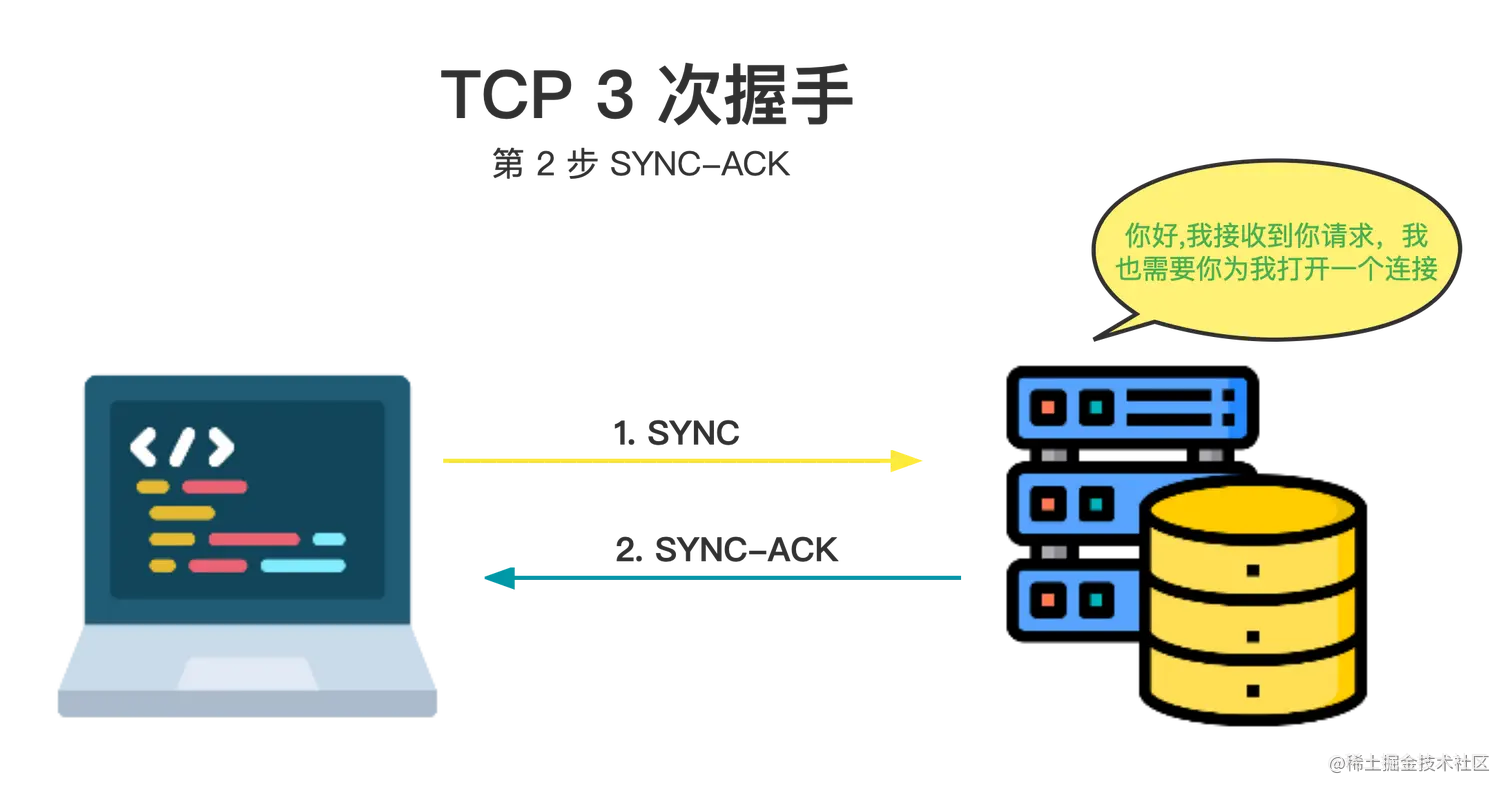
然后,服务器将回复一个 SYNC-ACK 消息( SYNChronization 和 ACKnowledgement)
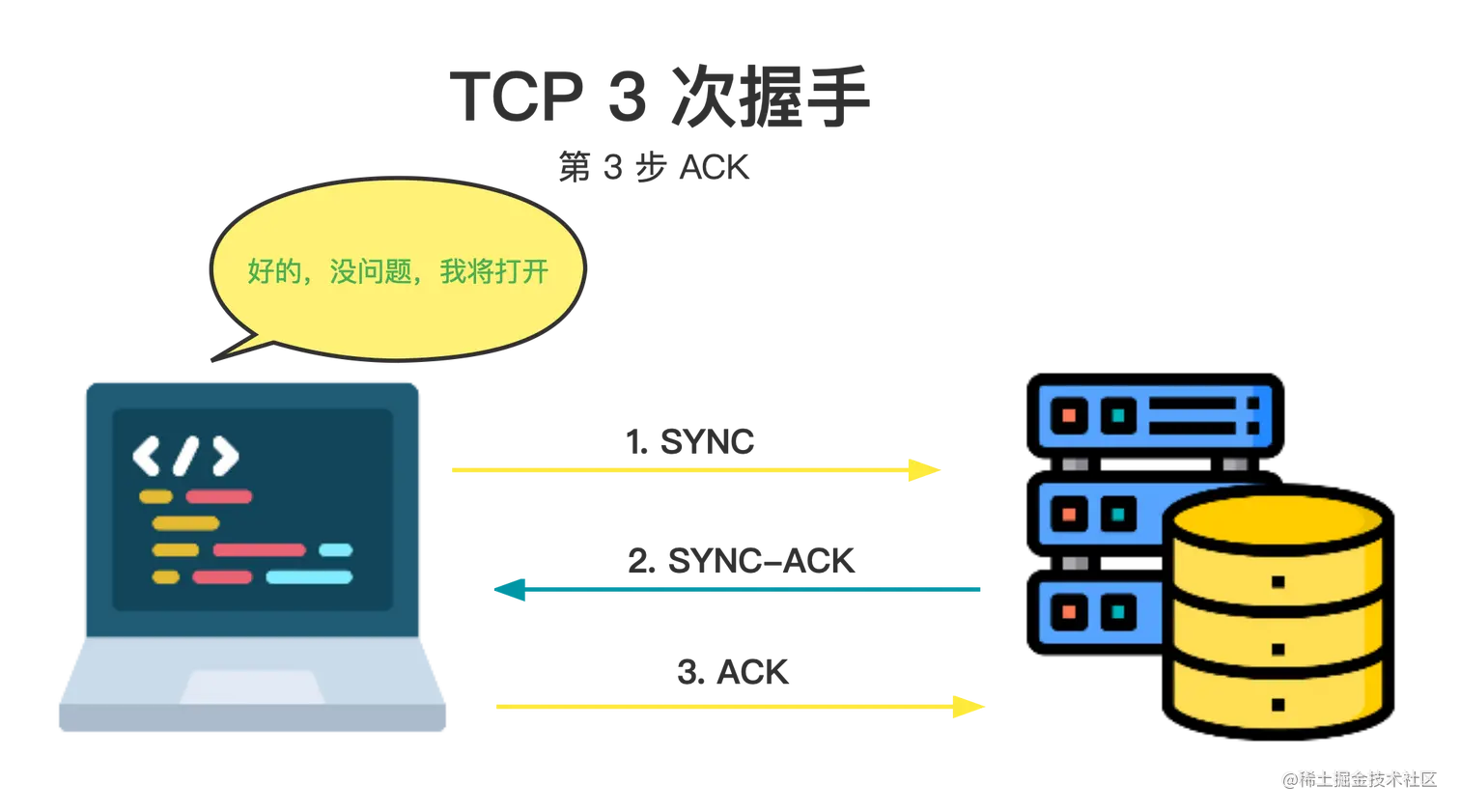
在最后一步,浏览器将回复一个 ACK 信息 现在,TCP连接(双向连接)已经通过3次握手建立,TLS协商可以开始。 TLS协商对于通过 HTTPS 建立的安全连接,需要进行另一次握手。这种握手(TLS协商)决定了哪个密码将被用于加密通信,验证服务器,并在开始实际的数据传输之前建立一个安全的连接。
在这一步骤中,浏览器和服务器之间还交换了一些信息
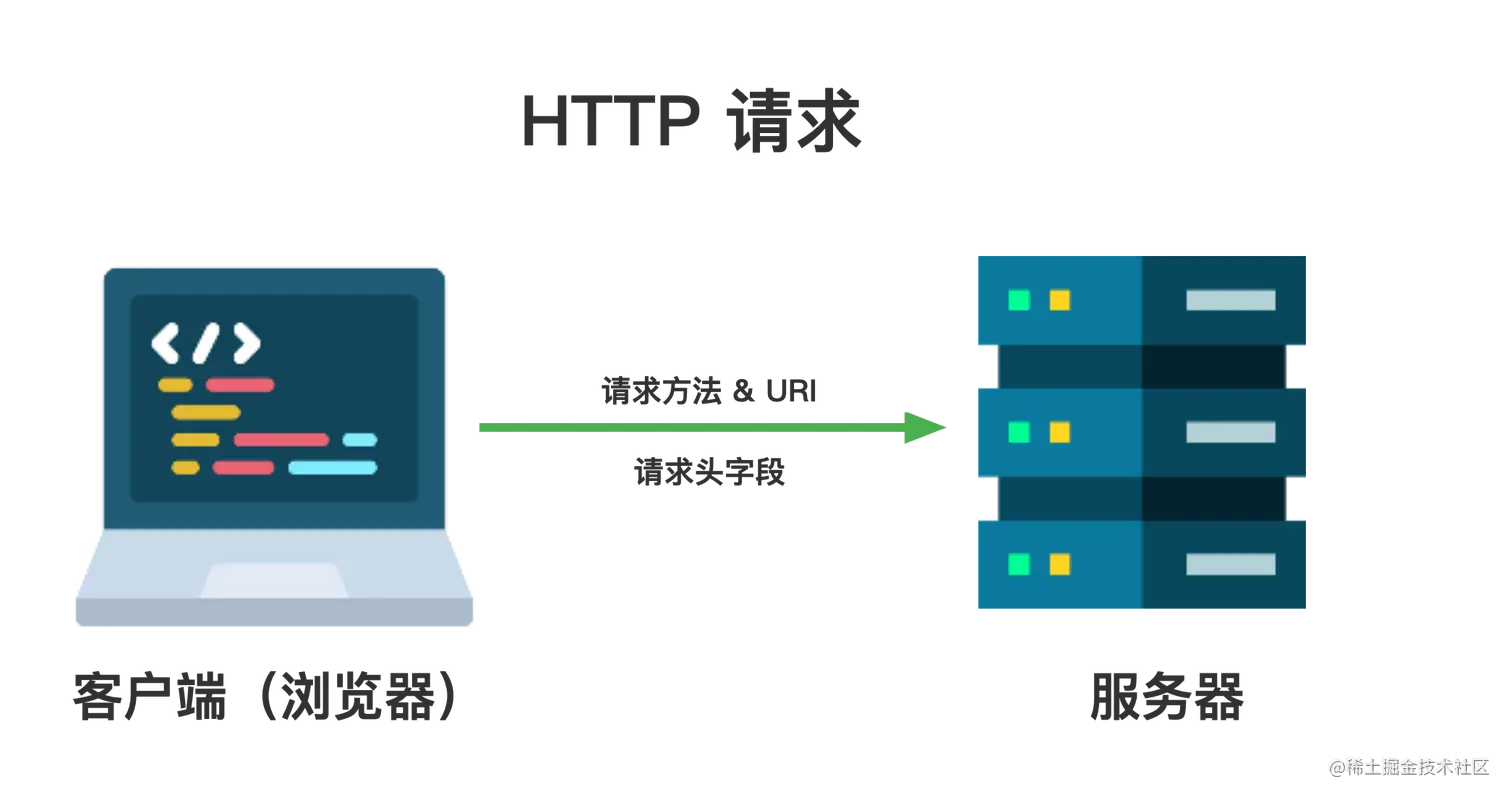
现在可以开始从服务器请求和接收数据了 2.获取数据在上一节中,我们谈到了 HTTP 请求在我们与服务器建立安全连接后,浏览器将发送一个初始的 HTTP GET 请求。首先,浏览器将请求页面的 HTML 文件。它将使用 HTTP 协议来做这件事。
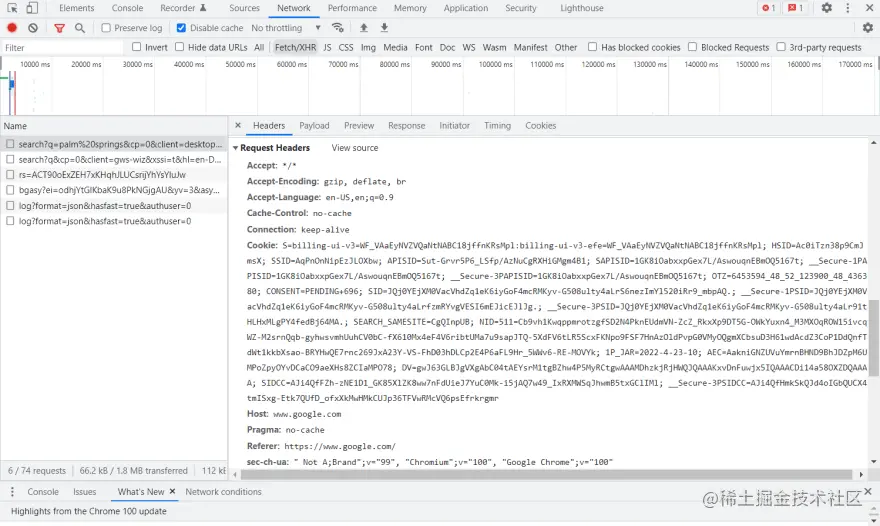
请求方法 - POST, GET, PUT, PATCH, delete 等 URI - 是统一资源识别符的缩写。URIs 用于识别互联网上的抽象或物理资源,如网站或电子邮件地址等资源。一个 URI 最多可以有 5 个部分 scheme:用于说明使用的是什么协议 authority:用于识别域名 path:用于显示资源的确切路径 query:用于表示一个请求动作 fragment:用来指代资源的一部分 // URI parts scheme :// authority path ? query # fragment //URI example <https://example.com/users/user?name=Alice#address> https: // scheme name example.com // authority users/user // path name=Alice // query address // fragment HTTP 头字段 - 是浏览器和服务器在每个 HTTP 请求和响应中发送和接收的字符串列表(它们通常对终端用户是不可见的)。在请求的情况下,它们包含关于要获取的资源或请求资源的浏览器的更多信息。 如果你想看看这些请求头字段是什么样子的,请进入 Chrome 浏览器并打开开发者工具(F12)。进入 Network 标签,选择
HTTP 响应一旦服务器收到请求,它将对其进行处理并回复一个
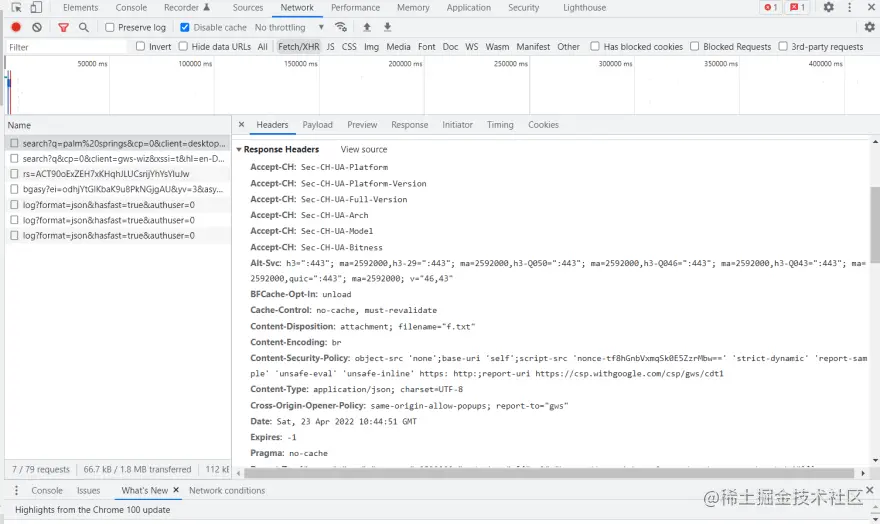
状态代码 - 例如:200、400、401、504网关超时等(我们的目标是 200 状态代码,因为它告诉我们一切正常,请求是成功的) 响应头字段 - 保存关于响应的额外信息,如它的位置或提供它的服务器。 一个 HTML 文档的例子可以是这样的 <!doctype HTML> <html> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <meta http-equiv="X-UA-Compatible" content="ie=edge"> <title>我的页面</title> <link rel="stylesheet" src="styles.css"/> <script src="mainscripts.js"></script> </head> <body> <h1 class="heading">这个是我的页面</h1> <p>一个段落和一个 <a href="<https://example.com/about>">链接</a></p> <div> <img src="myImage.jpg" alt="image description"/> </div> <script src="sideEffectsscripts.js"></script> </body> </html> 对于我前面提到的同一个搜索,响应头是这样的
如果我们看一下HTML文档,我们会发现它引用了不同的 CSS 和 Javascript 文件。这些文件不会被请求。在这个时候,只有 HTML 被请求并从服务器接收。 这个初始请求的响应包含收到的第一个字节的数据。第一个字节的时间(TTFB)是指从用户提出请求(在地址栏中输入网站名称)到收到第一个 HTML 数据包(通常为14kb)的时间。 TCP 慢启动和拥塞算法
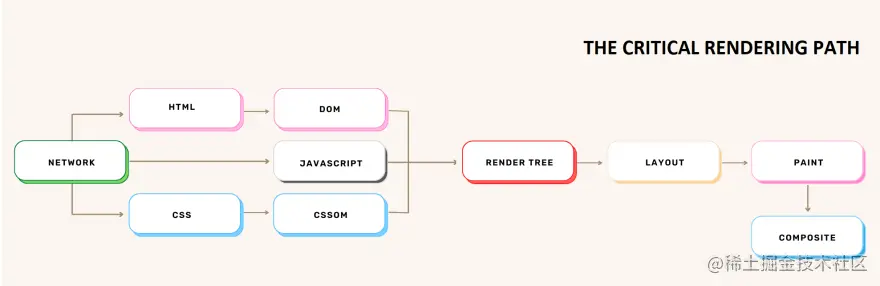
3.HTML 解析到目前为止,我们讨论了导航和数据获取。 今天我们将讨论解析,特别是 我们看到在向服务器发出初始请求后,浏览器如何收到包含我们尝试访问的网页的 HTML 资源(第一块数据)的响应。 现在浏览器的工作就是开始解析数据。
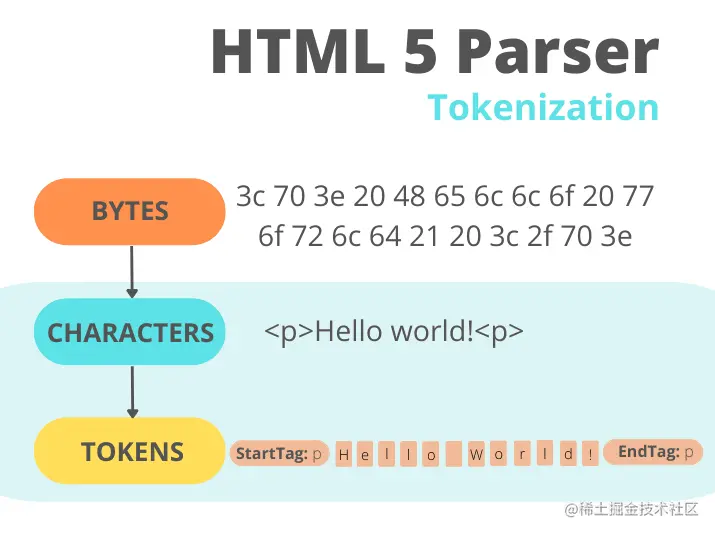
换句话说,解析意味着将我们编写的代码作为文本(HTML、CSS)并将其转换为浏览器可以使用的内容。 解析将由浏览器引擎完成(不要与浏览器的 Javascript 引擎混淆)。 浏览器引擎是每个主要浏览器的核心组件,它的主要作用是结合结构 (HTML) 和样式 (CSS),以便它可以在我们的屏幕上绘制网页。 它还负责找出哪些代码片段是交互式的。 我们不应将其视为一个单独的软件,而应将其视为更大软件(在我们的例子中为浏览器)的一部分。 有许多浏览器引擎,但大多数浏览器使用这三个活跃且完整引擎之一: Gecko 它是由 Mozilla 为 Firefox 开发的。 过去,它曾为其他几种浏览器提供支持,但目前,除了 Firefox,Tor 和 Waterfox 是唯一仍在使用 Gecko 的浏览器。 它是用 C++ 和 Javascript 编写的,自 2016 年起,还用 Rust 编写。 WebKit 它主要由 Apple 为 Safari 开发。 它还为 GNOME Web (Epiphany) 和 Otter 提供支持。 (令人惊讶的是,在 iOS 上,包括 Firefox 和 Chrome 在内的所有浏览器也由 WebKit 提供支持)。 它是用 C++ 编写的。 Blink,Chromium 的一部分 它最初是 WebKit 的一个分支,主要由 Google 为 Chrome 开发。 它还为 Edge、Brave、Silk、Vivaldi、Opera 和大多数其他浏览器项目(一些通过 QtWebEngine)提供支持。 它是用 C++ 编写的。 现在我们了解了谁将进行解析,让我们看看在从服务器接收到第一个 HTML 文档后到底发生了什么。 让我们假设文档如下所示: <!doctype HTML> <html> <head> <title>This is my page</title> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> </head> <body> <h1>This is my page</h1> <h3>This is a H3 header.</h3> <p>This is a paragraph.</p> <p>This is another paragraph,</p> </body> </html> 即使请求页面的 HTML 大于初始的 14KB 数据包,浏览器也会开始解析并尝试根据其拥有的数据呈现体验。 HTML 解析涉及两个步骤:词法分析 和 树构造(构建称为 DOM 树的东西)。 词法分析
词法分析过程结束时的结果是一系列 0 个或多个以下标签:DOCTYPE、开始标签 (
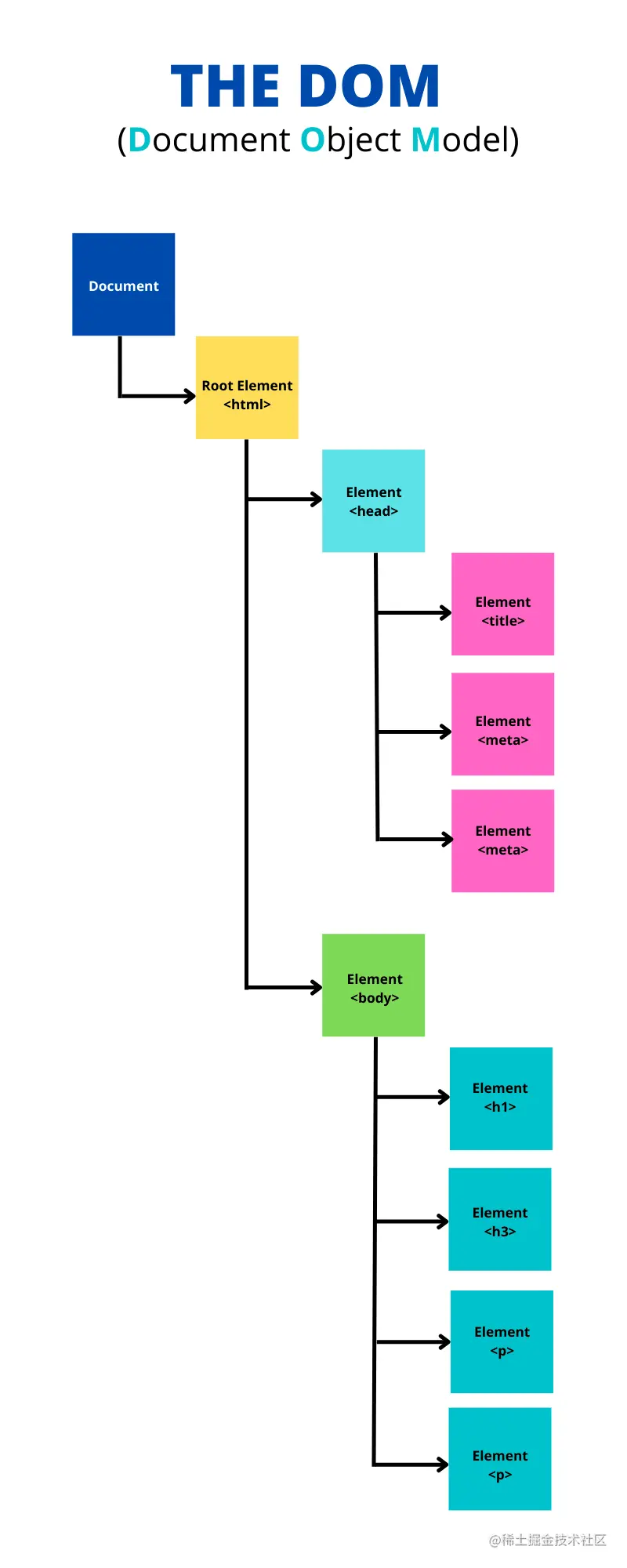
构建 DOM创建第一个 token 后, DOM 树描述了 HTML 文档的内容。
实际上,DOM 比我们在该模式中看到的更复杂,但我保持简单以便更好地理解(另外,我们将在以后的文章中更详细地讨论 DOM 及其重要性)。 此构建阶段是
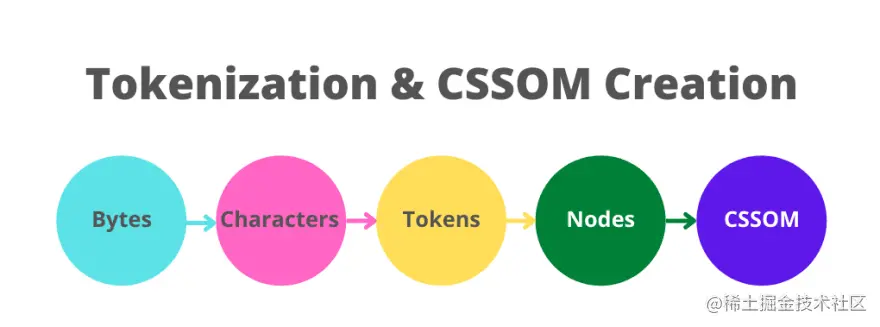
解析器从上到下逐行工作。 当解析器遇到非阻塞资源(例如图像)时,浏览器会向服务器请求这些图像并继续解析。 另一方面,如果它遇到阻塞资源(CSS 样式表、在 HTML 的 部分添加的 Javascrpt 文件或从 CDN 添加的字体),解析器将停止执行,直到所有这些阻塞资源都被下载。 这就是为什么,如果你正在使用 Javascript,建议在 HTML 文件的末尾添加 预加载器 & 使页面更快Internet Explorer、WebKit 和 Mozilla 都在 2008 年实现了预加载器,作为处理阻塞资源的一种方式,尤其是脚本(我们之前说过,当遇到脚本标签时,HTML 解析将停止,直到脚本被下载并执行)。 使用预加载器,当浏览器卡在脚本上时,第二个较轻的解析器会扫描 HTML 以查找需要检索的资源(样式表、脚本等)。 然后预加载器开始在后台检索这些资源,目的是在主 HTML 解析器到达它们时它们可能已经被下载(如果这些资源已经被缓存,则跳过此步骤)。 4.解析 CSS解析完 HTML 之后,就该解析 CSS(在外部 CSS 文件和样式元素中找到)并构建 CSSOM 树(CSS 对象模型)。 当浏览器遇到 CSS 样式表时,无论是外部样式表还是嵌入式样式表,它都需要将文本解析为可用于设置布局样式的内容。 浏览器将 CSS 变成的数据结构称为 CSSOM。 DOM 和 CSSOM 遵循相似的概念,因为它们都是树,但它们是 词法分析和构建 CSSOM与 HTML 解析类似,CSS 解析从词法分析开始。 CSS 解析器获取字节并将它们转换为字符,然后是标签,然后是节点,最后它们被链接到 CSSOM 中。 浏览器会执行一些称为
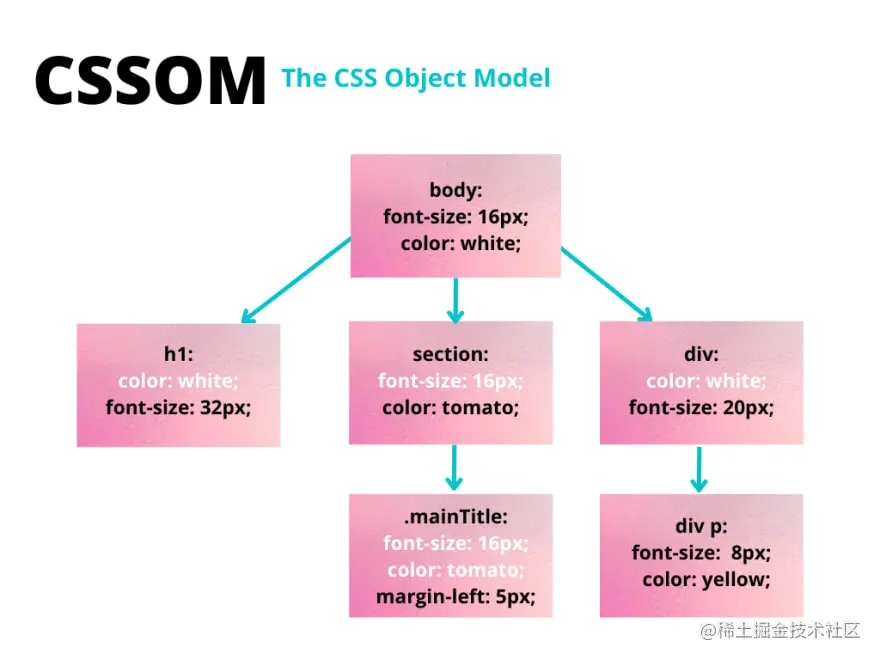
浏览器从适用于节点的最通用规则开始(例如:如果节点是 body 元素的子节点,则所有 body 样式都由该节点继承),然后通过应用更具体的规则递归地优化计算出的样式。 这就是为什么我们说样式规则是级联的。 假设我们有下面的 HTML 和 CSS: body { font-size: 16px; color: white; } h1 { font-size: 32px; } section { color: tomato; } section .mainTitle { margin-left: 5px } div { font-size: 20px; } div p { font-size: 8px; color: yellow; } 这段代码的 CSSOM 看起来像这样:
请注意,在上面的模式中,嵌套元素既有 由于我们的 CSS 可以有多个来源,并且它们可以包含适用于同一节点的规则,因此浏览器必须决定最终应用哪个规则。 这就是 想象一下,您在机场寻找您的朋友 John。 如果你想通过喊他的名字找到他,你可以喊 “ John ”。 可能不止一个 John 会同时出现在机场,所以他们可能都会做出回应。 更好的方法是用他的全名打电话给你的朋友,这样当你喊“John Doe”时,你就有更好的机会找到他,因为“ John Doe ”比“ John ”更具体。 同样,假设我们有这个元素:
<a href="<https://dev.to/>">This is just a link!</a> </p> 以及这些 CSS 样式: a { color: red; } p a { color: blue; } 您认为浏览器会应用哪条规则? 答案是第二条规则,因为 p 标签中的所有 a 标签选择器比所有a 标签选择器都具有更高的优先级。 如果你想玩玩优先级,你可以使用这个 优先级计算器。 重点CSS 规则是从右到左阅读的,这意味着如果我们有这样的代码: 5. 执行 Javascript在解析 CSS 并创建 CSSOM 的同时,还会下载其他资产,包括 Javascript 文件。 这要归功于我们在之前文章中提到的预加载器。
所以,当我们从服务器获取 Javascript 文件后,代码被解释、编译、解析和执行。 计算机无法理解 Javascript 代码,只有浏览器可以。 JS 代码需要被翻译成计算机可以使用的东西,这是 Javascript 浏览器引擎的工作(不要与浏览器引擎混淆)。 根据浏览器的不同,JS 引擎可以有不同的名称和不同的工作方式。 Javascript 引擎javascript 引擎(有时也称为 ECMAscript 引擎)是一种在浏览器中执行(运行)Javascript 代码的软件,而不仅仅是零部件(例如,V8 引擎是 Node.js 环境的核心组件)。 Javascript 引擎通常由 Web 浏览器供应商开发,每个主要浏览器都有一个。 我们说过,目前使用最多的浏览器是 Chrome、Safari、Edge 和 Firefox。 每个都使用不同的 Javascript 引擎,它们是: V8 V8 是 Google 的高性能 Javascript 引擎。 它是用 C++ 编写的,用于 Chrome 和 Node.js 等。 它实现了 ECMAscript(一种 Javascript 标准,旨在确保网页在不同 Web 浏览器之间的互操作性)和 WebAssembley。 它实现了 ECMA-262。 JavascriptCore JavascriptCore 是 WebKit 的内置 Javascript 引擎,它为 Safari 浏览器、邮件和 macOS 上使用的其他应用程序提供支持。 它目前按照 ECMA-262 规范实现 ECMAscript。 它也被称为 SquirrelFish 或 SquirrelFish Extreme。 Chakra Chakra 是微软为其 Microsoft Edge 网络浏览器和其他 Windows 应用程序开发的 Javascript 引擎。 它实现了 ECMAscript 5.1,并且对 ECMAscript 6 有部分(不断增加的)支持。它是用 C++ 编写的。 SpiderMonkey SpiderMonkey 是 Mozilla 的 Javascript 和 WebAssembly 引擎。 它是用 C++、Javascript 和 Rust 编写的,用于为 Firefox、Servo 和其他项目提供支持。 一开始,Javascript 引擎只是简单的解释器。 我们今天使用的现代浏览器能够执行称为即时 (JIT) 编译的功能,这是编译和解释的混合体。 编译 在编译过程中,一个称为
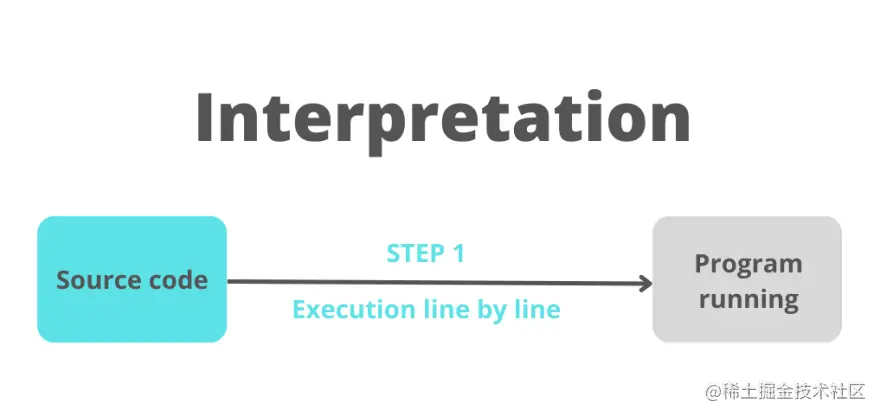
解释 在解释过程中,解释器逐行检查 Javascript 代码并立即执行。 没有进行编译,因此没有创建目标代码(代码的输出由解释器本身使用其内部机制创建)。 旧版本的 Javascript 使用这种类型的代码执行。
即时编译( JIT Compilation ) 即时编译是给定语言的解释器的一个特性,它试图同时利用编译和解释。 是在纯编译期间,代码是在执行之前被编译,然而在 JIT 编译中,代码在执行时(在运行时)被编译。 所以我们可以说源代码是动态转换为机器代码的。 较新版本的 Javascript 使用这种类型的代码执行。
简而言之,这三个过程可以总结为:
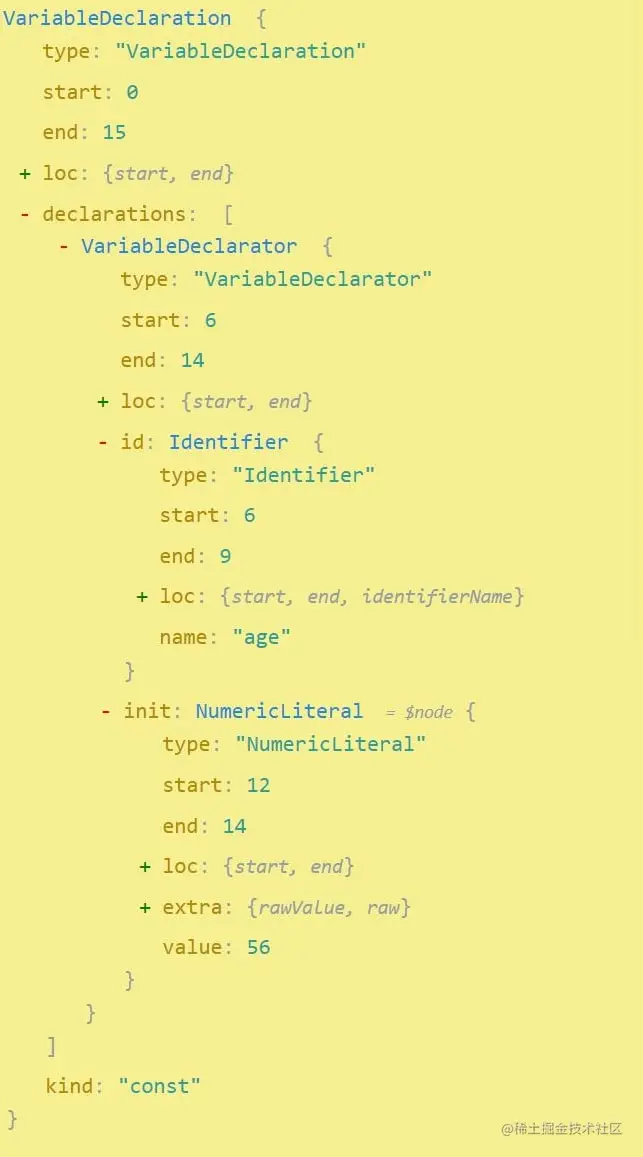
今天, 请注意,我提到了旧版本和新版本的 Javascript。 不支持较新版本语言的浏览器将解释代码,而支持的浏览器将使用某些版本的 JIT 来执行代码(V8、Chakra JavascriptCore 和 SpiderMonkey 引擎都使用 JIT)。 事实上,尽管 Javascript 是一种解释型语言(它不需要编译),但如今大多数浏览器都会使用 JIT 编译来运行代码,而不是纯粹的解释型语言。 Javascript 代码是如何处理的当 Javascript 代码进入 Javascript 引擎时,它首先被解析。 这意味着代码被读取,并且在这种情况下,代码被转换为称为 假设我们有一个文件,其中包含一个只做一件事的程序,那就是定义一个变量: js复制代码const age = 25; 这就是这行非常简单的代码看起来像抽象语法树的方式(我正在使用@babel/parser-7.16.12):
如果你想将一些 Javascript 转换为抽象语法树,你可以使用这个工具。 编写变量后得到的 AST 实际上要大得多,在屏幕截图中隐藏了更多节点。 构建 AST 后,它会被翻译成机器代码并立即执行,因为现代 Javascript 使用即时编译。 这段代码的执行将由 Javascript 引擎完成,利用称为“调用堆栈”的东西。
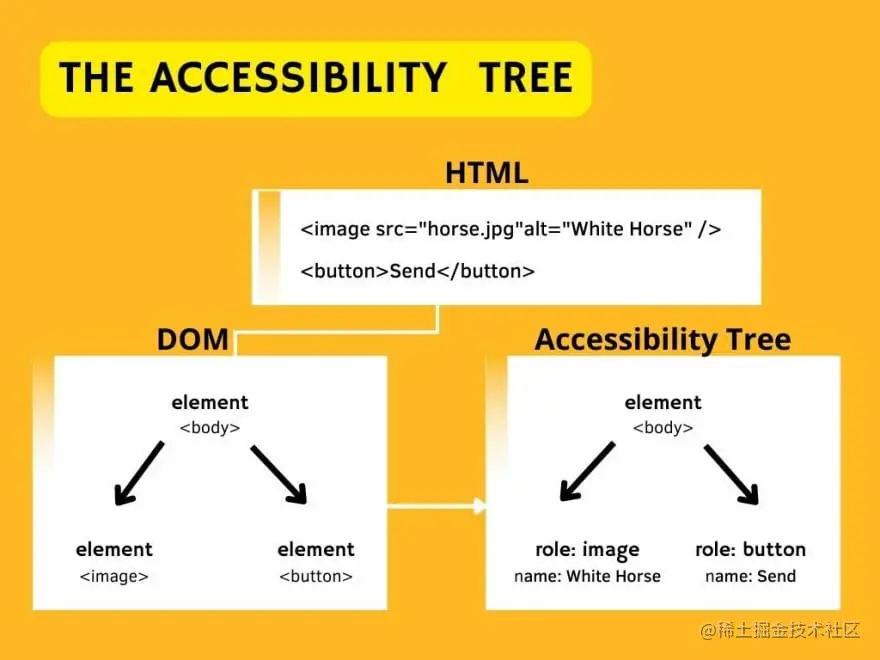
6.创建可访问(无障碍)树除了我们一直在讨论的所有这些树(DOM、CSSOM 和 AST)之外,浏览器还构建了一种称为
一般而言,残疾用户可以并且确实在使用具有各种辅助技术的网页。 他们使用屏幕阅读器、放大镜、眼动追踪、语音命令等。 为了让这些技术发挥作用,它们需要能够访问页面的内容。 由于他们无法直接读取 DOM,因此 ACT 开始发挥作用。 可访问性树是使用 DOM 构建的,稍后辅助设备将使用它来解析和解释我们正在访问的网页的内容。 ACT 就像 DOM 的语义版本,每次 DOM 更新时它都会更新。 每个需要暴露给辅助技术的 DOM 元素都会在 ACT 中有一个对应节点。 在未构建 ACT 之前,屏幕阅读器无法访问内容。
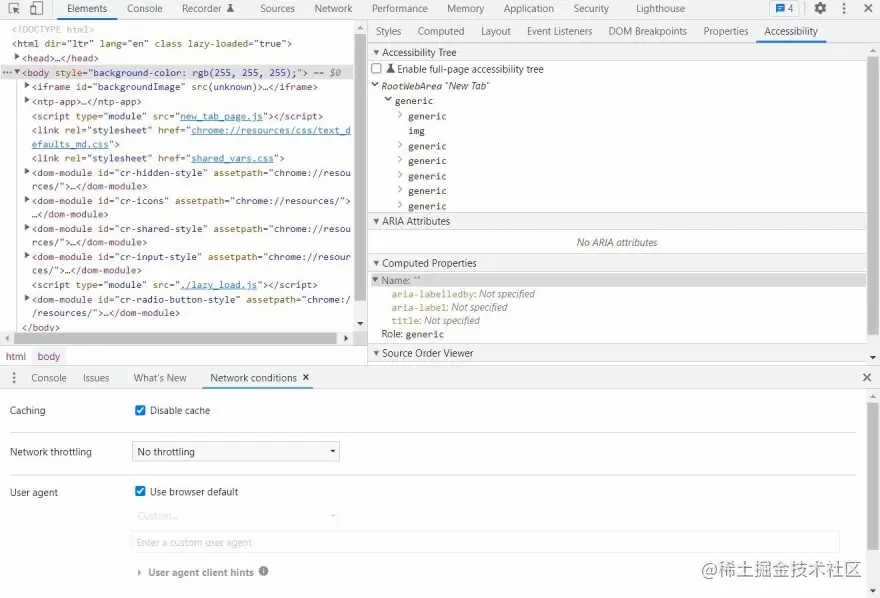
要查看可访问性树的实际的样子,您可以通过 Google Chrome 浏览器。 打开调试器 (F12) 并转到“元素”选项卡。 从那里,你可以在右侧选择“辅助功能”窗格。
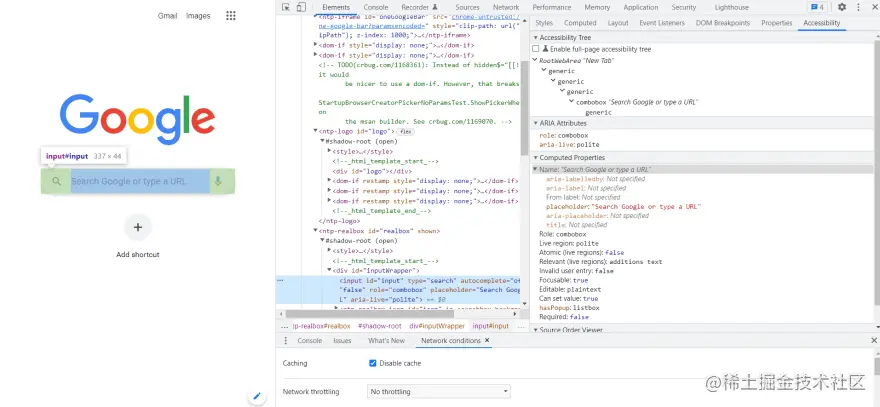
我去 Google 并检查了搜索输入,这是我在“计算”属性下的“辅助功能”窗格中得到的:
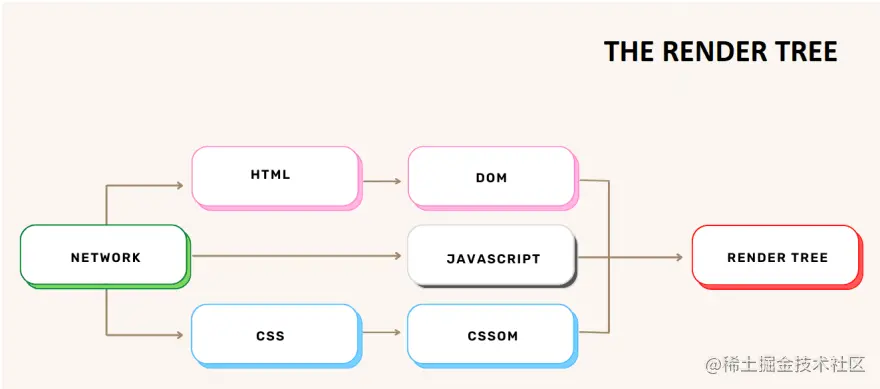
使用语义 HTML 的重要性超出了本文的范围,但作为开发人员,我们都应该记住,我们构建的网站应该可供所有希望使用它们的人使用。 如果您想阅读有关该主题的更多信息,可以在此处找到一篇关于 Web 可访问性的很好的介绍性文章。 据互联网协会无障碍访问特别兴趣小组称,目前全世界有超过 13 亿人(约占世界人口的 15%)患有某种形式的残疾。 7.渲染树在解析阶段构建的树(DOM、CSSOM)被组合成一种叫做 DOM 和 CSSOM 是使用 HTML 和 CSS 文件创建的。 这两个文件包含不同类型的信息,树的结构也不同,那么渲染树是如何创建的呢? 结合 DOM 和 CSSOM
以上步骤的结果将是一个包含所有可见节点、内容和样式的
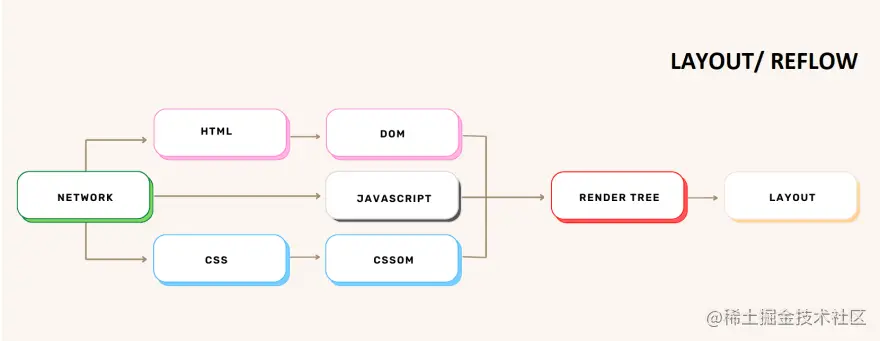
布局(回流)阶段渲染树包含有关显示哪些节点及其计算样式的信息,但不包含每个节点的尺寸或位置。 接下来需要做的是计算这些节点在设备视口(浏览器窗口内)内的确切位置及其大小。 这个阶段称为布局(在 Chrome、Opera、Safari 和 Internet Explorer 中)或重排(在 Firefox 中),但它们的意思相同。 浏览器在渲染树的根部开始这个过程并遍历它。
回流步骤不会只发生一次,而是每次我们更改 DOM 中影响页面布局的某些内容时,即使是部分更改,都会触发回流。 重新计算元素位置的情况示例如下:
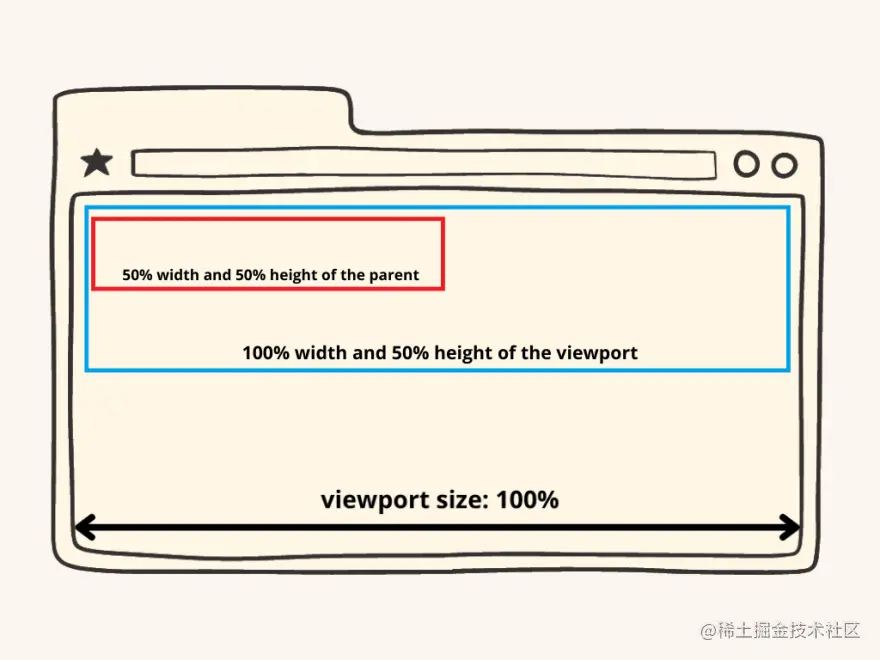
让我们来看一个非常基本的 HTML 示例,其中内嵌了一些 CSS: html复制代码<!DOCTYPE html> <html> <head> <meta name="viewport" content="width=device-width,initial-scale=1" /> <title>Reflow</title> </head> <body> <div style="width: 100%; height: 50%"> <div style="width: 50%; height: 50%">This is the reflow stage!</div> </div> </body> </html> 上面的代码只是说在视口内我们应该有两个 div,其中第二个嵌套在第一个里面。 父 div 占据视口宽度的 100%和高度的 50%。第二个 div 占据父 div 的 50% 这看起来像这样:
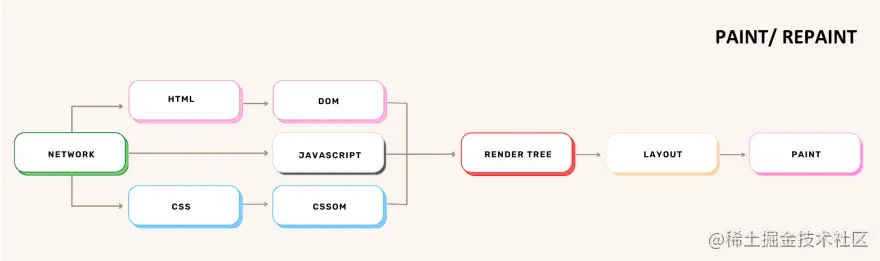
这个过程的输出是一个 绘画(重绘)阶段在浏览器决定哪些节点需要可见并计算出它们在视口中的位置后,就可以在屏幕上绘制它们(渲染像素)了。 这个阶段也被称为
就像布局阶段一样,绘画阶段不会只发生一次,而是每次我们改变屏幕上元素的外观时。 这些情况的例子是:
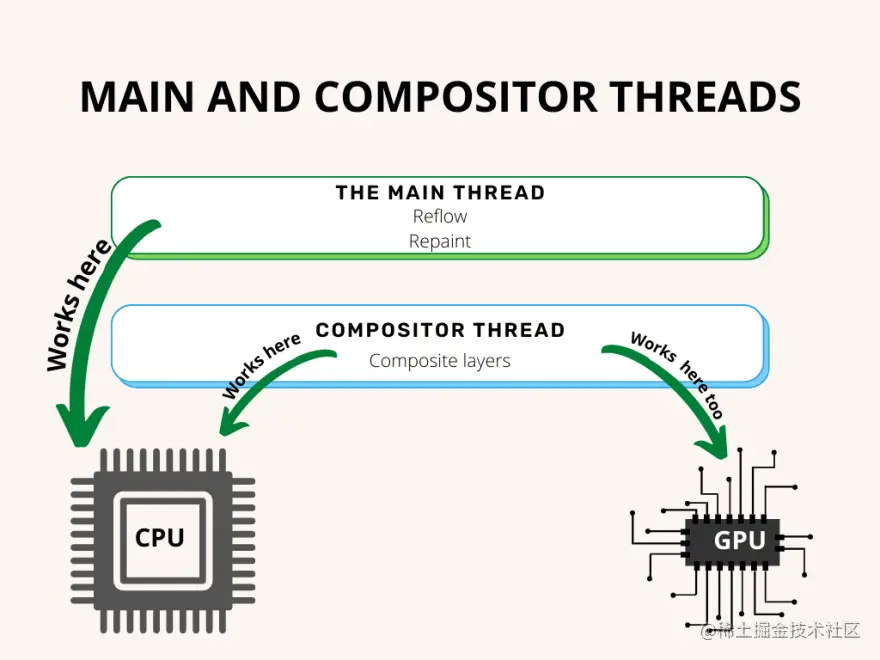
绘画意味着浏览器需要将元素的每个视觉部分绘制到屏幕上,包括文本、颜色、边框、阴影和替换元素(如按钮和图像),并且需要超快地完成。 为了确保重绘可以比初始绘制更快地完成,屏幕上的绘图通常被分解成几层。 如果发生这种情况,则需要进行合成。 分层和合成传统意义上,网络浏览器完全依赖 CPU 来呈现网页内容。 但现在即使是最小的设备也有高性能的 GPU,所有大部分实现方案都围绕着 GPU 来寻求更好的体验。
通常,只有特定的任务会被重定向到 GPU,而这些任务可以由合成器线程单独处理。 为了找出哪些元素需要在哪一层,主线程遍历布局树并创建层树。 默认情况下,只有一层(这些层的实现方式因浏览器而异),但我们可以找到会触发重绘的元素,并为每个元素创建一个单独的层。 这样,重绘不应应用于整个页面,而且此过程将可以使用到 GPU
如果我们想向浏览器提示某些元素应该在一个单独的层上,我们可以使用 谨记上面讨论的两种操作,回流和重绘,都是昂贵的,尤其是在像手机这样处理能力低的设备上。 这就是为什么在处理 DOM 更改时我们应该尝试优化它们(我将在我的 DOM 系列的未来一篇文章中详细讨论这一点)。 有些动作只会触发重绘,有些动作会同时触发回流和重绘。
链接:https://juejin.cn/post/7204806134935306301 该文章在 2023/5/25 18:17:19 编辑过 |
关键字查询
相关文章
正在查询... 



|


 400 186 1886
400 186 1886






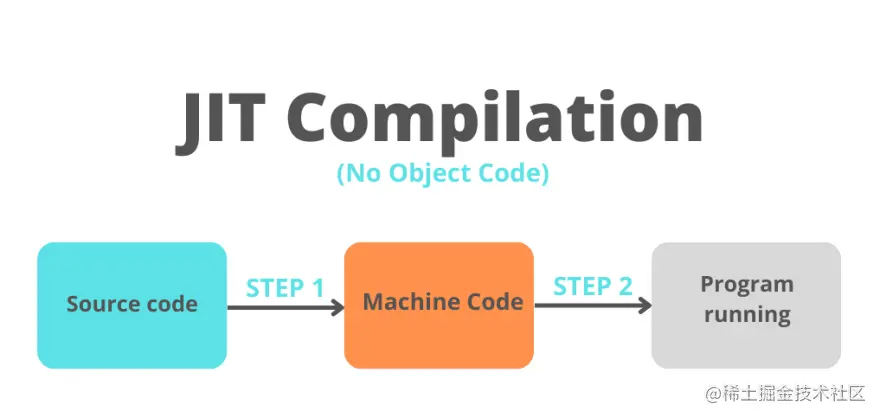 JIT 编译的一个很重要的方面就是将源代码编译成当前正在运行的机器的机器码指令。 这意味着生成的机器代码是针对正在运行的机器的 CPU 架构进行了优化。
JIT 编译的一个很重要的方面就是将源代码编译成当前正在运行的机器的机器码指令。 这意味着生成的机器代码是针对正在运行的机器的 CPU 架构进行了优化。